Music视频
@Music视频
21小时, 38 分钟 前在线-

macOS系统中微信等软件已授权截图与录像权限,但使用时仍反复弹出授权请求。
排查过程:尝试通过Codex环境自动检测,但因底层执行器故障(无法启动shell进程),未能直接读取或修改系统授权数据库。
原因分析:典型TCC隐私授权记录卡死、应用路径/签名变更,或tccd服务缓存异常。
修复步骤(已指导用户手动执行):
1. 完全退出微信及相关截图/录屏工具。
2. 打开终端,执行重置命令:
/usr/bin/tccutil reset ScreenCapture
/usr/bin/tccutil reset Microphone
(若仅针对微信,可执行:/usr/bin/tccutil reset ScreenCapture com.tencent.xin…[查看更多] -
acestep.cpp:跨平台本地AI音乐生成引擎(GGML + C++实现)
官方仓库GitHub – ServeurpersoCom/acestep.cpp
开发语言:C++ (C++17 标准)
核心框架:GGML
技术定位:ACE-Step 1.5 推理后端 / 离线音频生成引擎
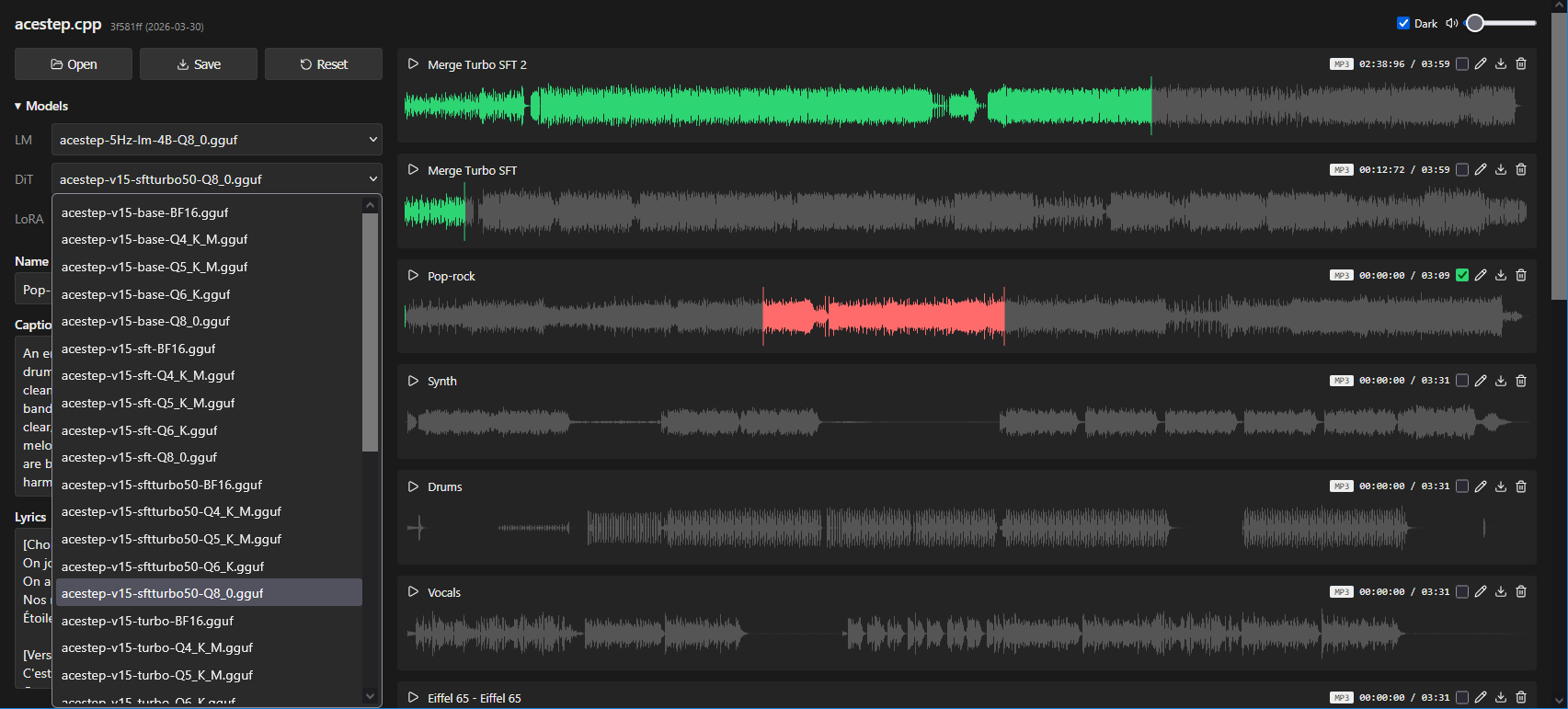
acestep.cpp 是一个基于 GGML 的跨平台本地 AI 音乐生成引擎,使用 C++17 实现 ACE-Step 1.5 推理后端,可在 CPU、CUDA、Vulkan、Metal、ROCm 等多种硬件上运行。项目支持文本生成音乐、歌词生成、音频合成与翻唱等功能,并提供完整 WebUI 与 HTTP API 服务。
用户只需输入音乐描述或歌词,…[查看更多]
-
请教老师,在DRAW THINGS中使用FLUX-2 KIEIN 9B 8-BIT想制作图生图产品图,如何 设置,能指导一下不.谢谢。
-
-
使用 agent 时,最好先把目标拆解成清晰的步骤,并提前规划任务流程,例如输入、处理、输出与验证,而不是只下达简单指令。结构化的任务规划可以减少反复修改,提高执行效率,并让模型更准确地理解需求,从而得到更稳定和可控的结果。
在使用 Agent 进行复杂任务时,很多人习惯直接输入一句简单指令,例如“帮我生成一个AI音乐项目介绍”或“写个安装教程”。这种方式虽然方便,但往往会导致结果不稳定,需要多次修改。
以acestep.cpp的文档整理为例,如果采用简单指令,Agent 可能只会输出一段泛化描述,缺少结构、重点不清晰,甚至遗漏关键功能。
而如果采用任务规划方式,效果会明显不同。可以先将任务拆解为四个步骤:
-
AI 大模型省 Token 技巧大全:9 个降低 API 成本与提升效率的方法
尽可能使用 CLI、规划任务、减少不必要的 Skill”非常切中要害,这些都是针对 Multi-Agent(多智能体,如 OpenAI Swarm 等框架)或自动化工作流的优秀优化策略。
在实际开发和调教大模型(尤其是多智能体/Swarm 架构)时,还可以从以下几个维度把 Token 压到极致:
4、善用 Prompt Caching(提示词缓存)
做法: 现代大模型(如 DeepSeek、GPT-4o)都支持缓存。在编写 System Prompt 或工具描述时,保持头部内容完全一致。
效果: 命中缓存的输入 Token 价格能打 1~2 折,能极大…
-
追光 在版块 NewVFX官方发布 ✅ 中回复了话题 《NewVFX架构说明及历程》不敢自满但无比自信 2周, 5天 前
2026年3月-6月11日:北京、朝阳。今年,我将主要精力聚焦于AI模型在内容与具体服务场景中的深度应用,而非对NewVFX进行更多的底层开发。
在技术学习方面,我着重掌握了SD系列模型,大幅提升了图片创作与精细化编辑的能力;同时,深入探索了Step ace 1.5模型在音乐制作上的潜力,并熟练应用了TTS(文本转语音)及Whisper(语音识别)等模型,有效打通了多模态内容生成的链路。
在业务实践上,我将大量时间投入到Agent(智能体)的应用落地中,致力于通过AI Agent优化具体服务流程,提升内容产出的效率与交互体验。这一策略转变让我更贴近实际业务需求,也为未来NewVFX的智能化服务升级积累了宝贵的实践经验。
-
对应M1至M5系列芯片的性能数据: Llama 7B 模型在不同量化精度下的性能测试数据
Apple M系列芯片 Llama 7B 性能对比表1. M1系列 (第一代Apple Silicon)
型号
GPU核心
内存带宽 (GB/s)
F16 PP (t/s)
F16 TG (t/s)
Q8_0 PP (t/s)
Q8_0 TG (t/s)
Q4_0 PP (t/s)
Q4_0 TG (t/s)
M1
8
68
–
-
在人工智能和大语言模型(LLM)爆火的今天,无论是开发者还是普通用户,都不可避免地遇到一个词Token(令牌/词元)。买 API 额度时,商家按“每百万 Token”开价;和 AI 聊天时,界面会提示“上下文 Token 限制”。那么,这个神秘的 Token 究竟是什么?它是怎么来的?又是如何决定你钱包里银子流向的?今天我们就来彻底扒一扒大模型背后的这套“硬通货”。
一、 Token 的由来:AI 是如何“识字”的?
要理解 Token 的由来,首先要明白一个底层逻辑:计算机本质上是个“数学脑袋”,它根本不认识人类的文字。
无论是汉字、英文单词、数字还是标点符…[查看更多]
-
这些参数是控制acestep.cpp(Turbo 模型) AI 音乐生成效果的核心“旋钮”。下面拆解这些参数的物理含义和调整建议。
一、 DIT FLOW MATCHING (DiT 扩散模型参数)
这是决定“声音质量”的引擎。
Inference Steps (推理步数)
意义:扩散模型去噪的次数。步数越多,细节越细腻,但越耗时。
Turbo 模型建议:官方预设是 8,你设为 12 是合理的,能稍微增加一点稳定性。不需要过高,否则反而可能产生噪音。Guidance Sca…[查看更多]
-
追光 在版块 Hermes Agent 实际使用案例 中发起了话题 Hermes Agent 实际使用案例 1个月 前
📖 目录
- [初始设置案例](#初始设置案例)
- [日常开发工作流](#日常开发工作流)
- [消息平台集成](#消息平台集成)
- [多环境管理案例](#多环境管理案例)
- [故障排查案例](#故障排查案例)
- [高级用法案例](#高级用法案例)
初始设置案例
案例 1: 首次安装和配置
bash
# 步骤 1: 安装
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash# 步骤 2: 进入安装目录
cd ~/.hermes/herm…[查看更多] -
追光 在版块 📺 VFX Pipeline | 数字创意工作流 中发起了话题 Hermes Agent 命令速查表 1个月 前
.hermes-cheatsheet { max-width: 100%; overflow: hidden; box-sizing: border-box; font-family: system-ui, -apple-system, “Segoe UI”, Roboto, sans-serif; line-height: 1.6; color: #1f2937; } .hermes-cheatsheet h2, .hermes-cheatsheet h3 { margin: 1.5em 0 0.5em; line-height: 1.25; } .hermes-cheatsheet h2 {…[查看更多]
-
追光 在版块 📺 VFX Pipeline | 数字创意工作流 中发起了话题 Hermes Agent 完整命令参考手册 1个月 前
📚 目录
- [安装与初始化](#安装与初始化)
- [基础交互命令](#基础交互命令)
- [配置管理命令](#配置管理命令)
- [工具与技能管理](#工具与技能管理)
- [Profile 多环境管理](#profile-多环境管理)
- [网关与消息平台](#网关与消息平台)
- [诊断与维护](#诊断与维护)
- [高级选项与参数](#高级选项与参数)
安装与初始化
🚀 安装
bash
# 1. 交互式安装(推荐,首次使…[查看更多] -
macOS 推荐使用原生 launchd 实现登录自启,支持后台常驻、崩溃自动重启,且不影响终端会话。
1. 创建日志目录
mkdir -p ~/.hermes/logs2. 编写自启配置文件
cat > ~/Library/LaunchAgents/com.hermes.gateway.plist << 'EOF'Labelcom.hermes.gateway
ProgramArguments/Users/xbaby/.hermes/hermes-agent/venv/bin/hermes
gatewayWorkingDirectory/User…[查看更多]
-
无需公网服务器、无需 Webhook、支持个人微信直连。本文是 Hermes Agent 的安装、配置与启动,并结合 LLM Wiki 与 Obsidian,搭建一套可长期演进的 AI 知识沉淀工作流。适合开发者、知识工作者与 AI 爱好者实操。
一、环境准备
在开始部署前,请确保你的运行环境满足以下基础条件:一个可正常登录的个人微信账号;Python 3.8+ 运行环境;具备 pip 与终端命令行权限的 Linux / macOS / Windows(WSL)系统
htt…[查看更多]
-
ACE-Step 全栈部署与大版本架构迁移全纪录。它完整记录了我们如何将本地前端外壳,与 2026-05-16 发布的全新硬核 C++ 引擎(基于 Apple Silicon Metal 加速)完美缝合的整个历程。
可以直接复制保存这篇日志,作为日后复现或团队分享的技术文档。
ACE-Step-CPP-UI 部署与全新引擎适配通关日志
一、 环境与背景
硬件平台:Apple M1 Pro (Unified Memory 架构,支持 bfloat 与 Metal 硬件加速)。
软件堆栈:Node.js / TypeScript (Frontend & Server) + C++ GGML/Metal (Core Engine)。
引擎版本…[查看更多] -
pinokia版本的Ace step Ui在实践中的吞字问题,和无法使用添加乐器、编曲功能
目前在 Mac 的 MLX 生态中,官方及社区仅推出了 Turbo 这一款加速版模型。虽然它能8步就能出歌,但因为砍掉了语言模型(LM)的对齐逻辑,导致它有着极易“吞字、漏字”的顽疾,且在 MLX 下无法使用 Base 和 SFT 版本。不能使用 MLX 的其他版本(Base/SFT),最核心的原因并不是 Mac 硬件不支持,也不是Ace Step Ui不支持而是开源社区压根就没有做出这些格式的模型文件。
如果想在Mac上解锁 ACE-Step 1.5 的完整实力,强烈建议转向基于 GGUF 格式的 C++ 生态(如 acestep-cpp-ui):
功能全开:完美支持 GGUF 格式…[查看更多]
-
这是一个用于 macOS 的 Hermes WebUI 自动化启动与守护安装脚本,用于一键配置 launchd 服务,使 WebUI 在系统登录后自动启动并保持运行。脚本首先清理旧的 launchd 配置,避免因残留任务导致冲突或重复加载,然后在用户的 LaunchAgents 目录中重新生成标准 plist 文件。该配置通过 ProgramArguments 直接调用 start.sh 脚本,避免使用 cd && 等复杂 shell 组合,从而提升 launchd 执行的稳定性与兼容性。同时脚本会自动执行 plist 语法校验,确保 XML 格式正确无误
cat < ~/install_hermes_webui.sh
#!/bin/bashset -e…[查看更多]
-
在本地或服务器环境中安装并运行 Hermes 的 Web 图形界面(Hermes WebUI),用于与 Hermes / LLM Agent 进行可视化对话交互。通过该界面,用户可以在浏览器中直接与大语言模型进行实时对话,并观察 Agent 的响应过程与工具调用情况。
安装流程通常包括获取项目代码、配置运行环境以及启动本地服务三部分,确保依赖组件(如 Python、Node.js 或相关运行时)已正确安装。启动后,系统会在本地或指定服务器端口提供 Web 访问地址,用户可通过浏览器打开图形界面进行…[查看更多]
-
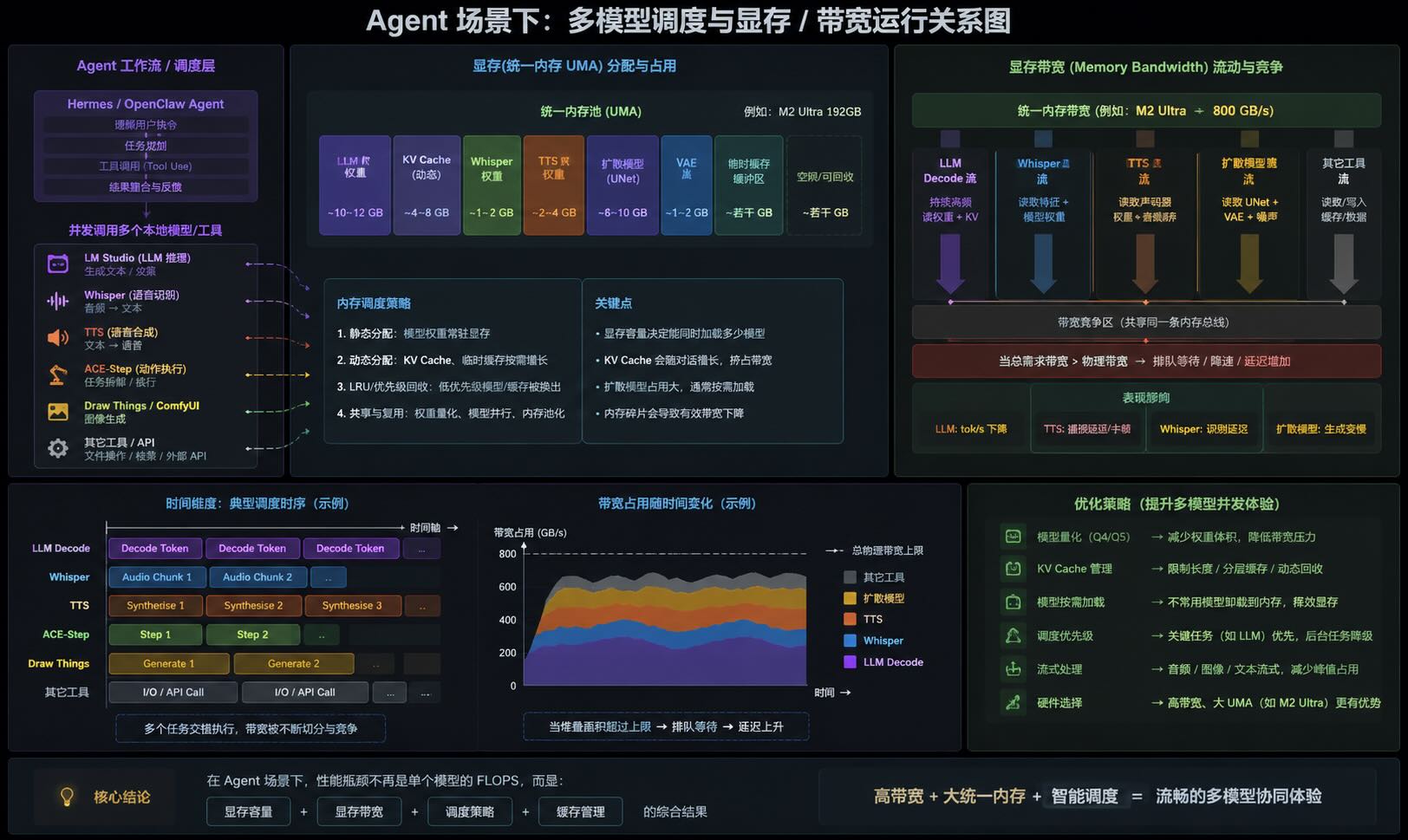
为什么 Agent 会把“显存带宽问题”无限放大
传统本地大模型通常只有:一个 LLM,一个 KV Cache,一个 Decode 循环,但在 Hermes、OpenClaw 这类 Agent 系统中,大模型已经不再只是“聊天机器人”,而更像一个 AI 调度中枢(Orchestrator)。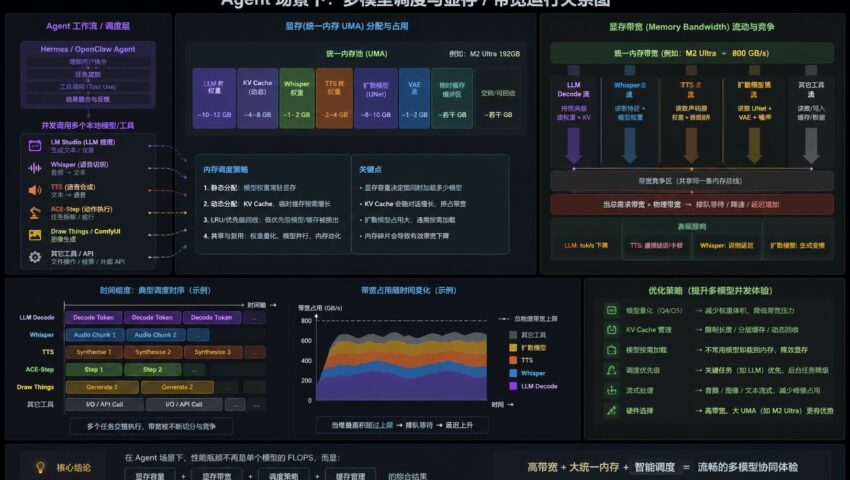
我经常使用的场景是这样的:
LM Studio:负责主 LLM 推理;Whisper:负责语音识别;TTS:负责语音合成;ACE-Step:负责音乐制作;Draw Things / ComfyUI:负责图像和视频,此时系统实际上是在同…[查看更多]
-
✦ Apple Silicon 显存带宽对推理速度的真实影响(M1 Pro vs M2 Ultra)
以 Apple Silicon 为例,可以非常直观地理解“Decode 阶段为什么被显存带宽限制”。
在本地运行大模型时,Decoding 阶段的速度在很大程度上近似受以下关系约束:
在 Apple 的统一内存架构(UMA)下,CPU 与 GPU 共享同一块高带宽内存,因此显存带宽直接决定了模型“逐 token 读取权重”的上限。
以实际芯片为例:
* M1 Pro:统一内存带宽约
-
Hermes Agent优化首轮对话prompt方法与智能程度的方法
要优化 Hermes 的首次提交速度并解决幻觉,必须去它的用户目录(通常在 ~/.hermes/)对后台自动生成的 Markdown 文件进行物理裁剪,将前缀控制在 500字(2000字符) 以内。
一、 物理剔除不准确的“伪记忆”
Hermes 会在后台偷偷把历史对话的错误推论写进文件,导致首次开机时不仅慢,还会携带错误认知。进入目录:
cd ~/.hermes/memories/打开 MEMORY.md(事实记忆)与 USER.md(用户偏好)。
像删坏代码一样,物理整行抹去过期的环境变量、废弃的临时信息和错误的业务推论。只留下你真正要的语气和世界观(S…[查看更多]
- 查看更多