Music视频
@Music视频
2天, 6小时 前在线-

最近我一直在想,如果一个影视剧中用到多个角色、能不能把角色制作成Lora,这样角色就能迁移、需要几个角色、只需要调用对应的ora组合就可以。想让AI 生成的各种场景中保持脸部、妆容一致,这就需要用到训练自己的ai Lora,通过 Draw Things 就能在本地训练属于自己的 LoRA 模型,当然也可以通过Comfyui等工具来训练。本文将基于最新的 FLUX.2/SD 架构界面,训练自己的AI 角色Lora。
训练AI 角色Lora操作方法
1. 准备数据集 (Dataset)
在界面的右侧 Dataset 区域:
添加图片: 点击 “Add” 按钮,上传 15-25 张…[查看更多]
-
这套方法的精髓在于利用 Qwen Image Edit 的局部编辑能力,配合 F2P (Face to Portrait) LoRA,实现从单一“脸部照片”到“全身/多风格肖像”的高保真转换。
一、 环境与资源准备
1. 基础模型:选择 Qwen Image Edit(基于通义千问的图像编辑模型)。
2. LoRA:加载 F2P LoRA(由 ModelScope 社区 Dent Studio 提供,基于一万多张高质量人像训练,兼顾特征一致性与人体审美)。
3. 软件工具:推荐使用 Draw Things 进行本地部署与操作。

二、 基础操作流程
-
使用SD ControlNet pose精准控制AI表情、手指与姿势:进阶工作流
第一步:提取完整骨架(含脸/手)
访问「哩布哩布AI」网站,上传参考图。ControlNet 类型选 OpenPose,预处理器务必选择 OpenPose Full。系统将输出包含身体坐标、手指关键点与面部五官点位的完整骨架图。这是实现同步控制的数据基础。第二步:导入 DrawThings 图层
将生成的骨架图拖入 DT 的 Pose 图层,或放入draw thi…[查看更多] -
很多人用 AI 画图,最大的痛点根本不是不会写提示词,而是“人物姿势总乱变”。同样输入“一个站立的人”,AI 可能随机生成几十种完全不同的姿态。做分镜、角色设计或视觉预演时,这种不确定性非常致命。
解决这个问题的核心工具就是 Pose ControlNet。它的作用很直接:把“人物怎么动”从 AI 的随机发挥中抽离出来,变成你可以完全掌控的固定框架。
下面以 DrawThings 为例,走一遍最清晰、最稳定的按照我们的预期动作生成图片的操作流程。文末附你提供的完整参数配置对照表,ComfyUI 用户可直接按相同数值平移。
-
在最新的 AI 图像编辑领域,QIE-2511 AnyPose 提供了一种新的姿态迁移思路:不再依赖 OpenPose 骨架提取,而是直接通过图像理解实现动作迁移。该方法基于 Qwen Image Edit 2511,并结合 AnyPose LoRA,实现仅通过参考图片即可驱动人物动作变化。

一、核心思路
传统姿态迁移依赖 OpenPose 先提取人体骨架,再将骨架作为控制信号生成图像。这种方式结构稳定,但表达能力有限。
AnyPose 的核心变化是:直接使用“图像”作为姿态信号,由模型自行理解动作结构。也就是说,模型不再依赖显式骨架,而是通过视觉理解完成隐式姿态建模,使动作更加自然灵活。
二、模型…[查看更多]
-
追光 在版块 💻 Nuke合成影视制作 中发起了话题 CorridorKey:AI 如何重新定义绿幕抠像【AI制作】 2天 前
在影视后期制作中,绿幕抠像一直是最基础却也最耗时的环节之一。无论是使用 Keylight、Primatte,还是各种 AI roto 工具,行业的核心问题始终没有真正解决:当主体边缘与绿幕发生颜色混合时,如何准确地还原真实前景。
传统方法的思路是“分离”——通过颜色判断生成 Alpha 遮罩,再配合 edge refine、despill、roto 等流程不断修补细节。然而这种方式本质上是在做二值或半连续的分类,它很难处理头发、运动模糊、半透明材质等复杂情况,最终往往需要大量人工干预。
CorridorKey 的出现,提出了一个完全不同的思路:不再去判断“哪里是前景”,而是直接重建“前景本身”。
它的核心能力在于对图像进行“反混合”(unmixing)。在绿幕拍摄…[查看更多]
-
随着生成式图像技术的发展,图像编辑正在从“工具操作”转向“语言驱动”,Qwen Image Edit、Fluxkelein2等模型正是这一趋势下的代表模型。它可以在本地(如 Draw Things)运行,通过简单的提示词完成复杂的图像生成与编辑任务。在许多场景中,它已经可以替代传统依赖 LoRA 或复杂流程的工作方式。
本文将系统梳理 Qwen Image Edit 的核心能力与实际应用场景。
一、人物一致性与多场景生成
Qwen Image Edit 可以基于一张人物基础图,生成该角色在不同场景下的表现,同时保持人物外观的一致性。
例如,同一个人物可以被快…[查看更多]
-
最近在设计圈和社交媒体上,两种视觉风格非常火:霓虹玻璃面板社交名片,玻璃棱镜光谱 Logo,它们的共同特点是:未来感强、信息清晰、视觉高级。这篇教程将手把手教你,用 Qwen Image + Draw Things 实现这两种效果,而且是稳定、可控、可定制的专业流程。这里流程中使用的模型主要有俩种生图模型、图片编辑模型、可以使用qwen 模型也可以使用flux2、z image或者其他你喜欢的模型来制作。主要展示流程和提示词写。

一、核心方法思路(一定要先理解)
很多人会尝试“一步生成”,但效果往往:文字崩坏,排版混乱,不可控。
👉 正确方法是:…[查看更多]
-
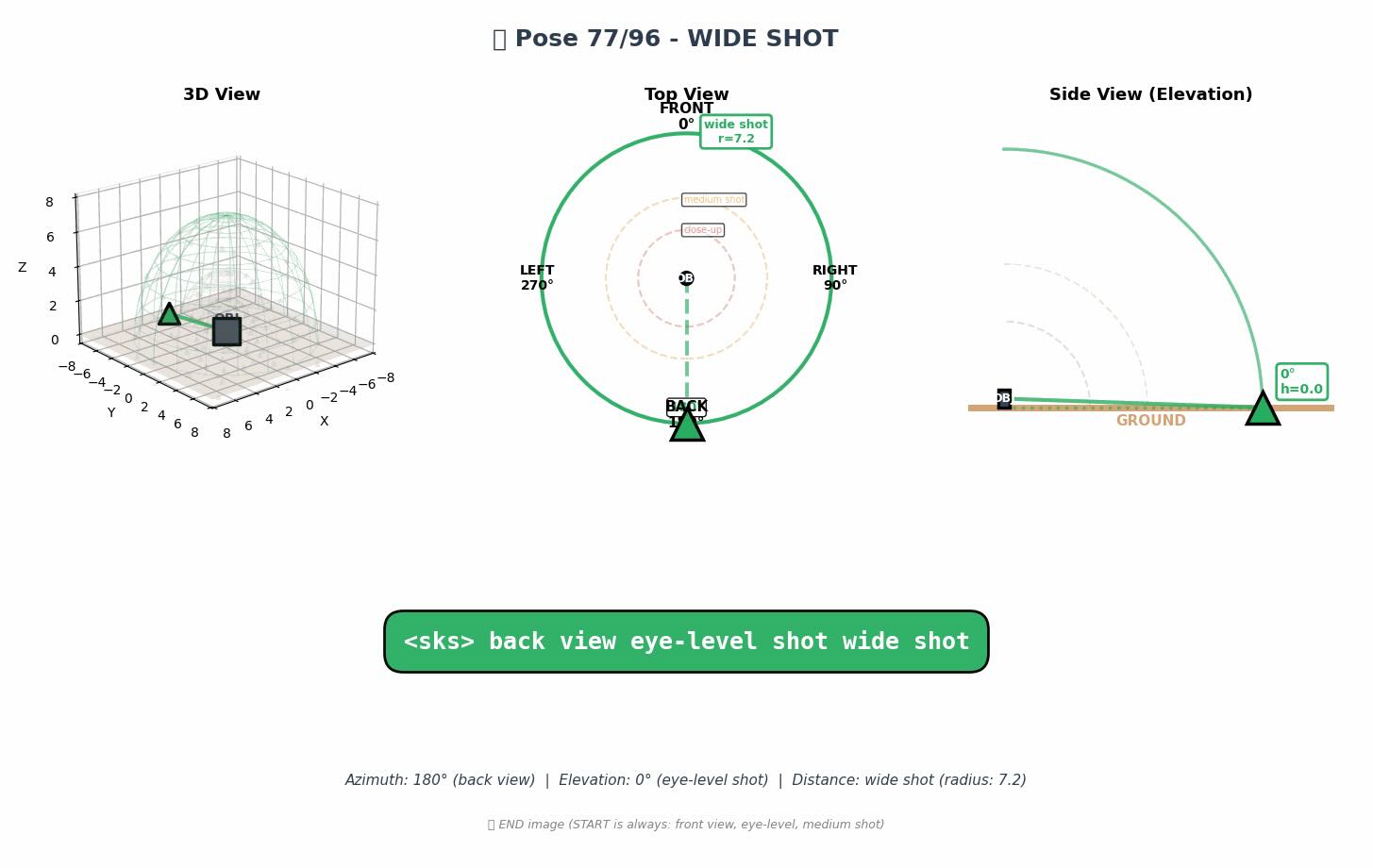
为了精准控制AI出图视角,我把 Qwen-Image-Edit-2511-Multiple-Angles-LoRA 的所有官方参数组合做成了结构化提示词库。8大方位 × 4种仰角 × 3种景别 = 96组标准写法,已按「正面/45°/侧面/背面」分段整理,每组自带使用场景备注,画角色卡、商业图,影视、游戏场景设计。
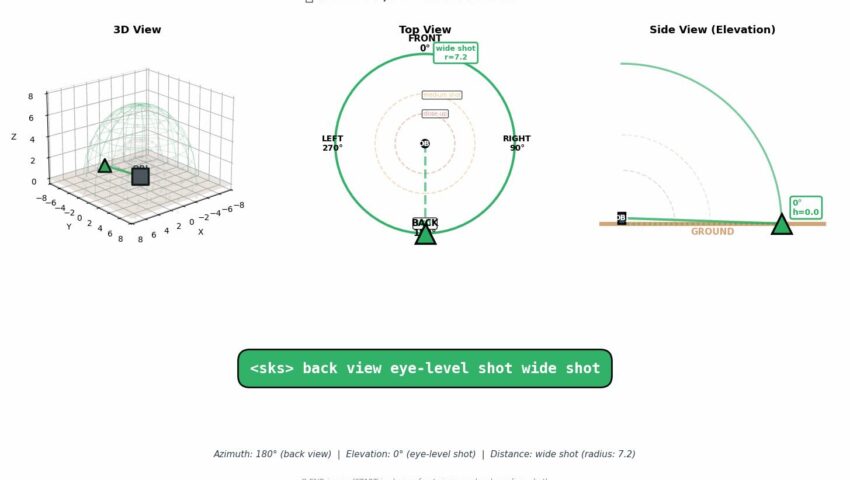
🔹 核心语法: [方位] [仰角] [景别](严格空格分隔,禁加标点/括号) 🔹 适用底模:Qwen/Qwen-Image-Edit-2511/2509 🔹 参数建议:LoRA强度 0.85~1.0,固定 Seed 可稳定生成角色三/四视图
该提示词可以在Comfyui和Draw things等调用支持Qwen image edit(1.0版本、2509…[查看更多]
-
六、Draw Things物体移除功能(Object Removal)流程
本工作流利用 Flux Fill 强大的图像填充能力结合专用 LoRA,实现对画面中多余物体的无痕移除与背景补全。
1. 核心模型配置
主模型: flux1filldevq8p.ckpt
专用 LoRA: Object Removal Flux Fill v2(JSON 中对应文件为 fluxoutpaintloraloraf16.ckpt)
LoRA 触发提示词: Fill the green spaces according to the image,2. 操作步骤
1. 图片导入: 将包含想要移除物体的图片…[查看更多]
-
五、从肖像到全身绘图
本工作流利用 Qwen 架构的图像编辑模型,结合人脸保持 LoRA,实现仅需一张面部参考图,即可生成指定人物的全身、场景照片。
1. 操作流程
1.1 放置参考脸: 在 ControlNet 的 Moodboard 单元中,放入目标人脸图片(图2)。
1.2 生成目标图像: 在画布内,直接输入你想要生成的人物全身描述、着装、姿势及场景提示词。软件将自动提取 Moodboard 中的面部特征进行生成。
2. 完整工作流配置 (JSON)
配置方案:M4/M5 芯片 M 系列 Mac/iPad 高效生成
注意: 此配置使用了 4 步加速 LoRA,并精确调配了人脸保持 LoRA 的权重(0.6),以平衡面部…[查看更多] -
四、模糊照片变清晰(照片修复与高清放大)
本工作流利用 Qwen 架构的图像编辑模型结合专用修复 LoRA,实现将模糊、低分辨率照片重塑为高清画质。
推荐模型搭配:
主模型: qwen_image_edit_2509加速 LoRA: qwen_image_edit_2509_lightning_4_step
修复 LoRA: lora_a_qwen_edit_enhance_64_v3_000001000
1. 核心模型与脚本流程
标准操作流程:
第一步(清晰化): 使用脚本 “enhance”,利用专用修复 LoRA 先将模糊的底图变清晰。第二步(放大): 清晰化后,再使用…[查看更多]
-
三、 Draw Things替换人脸流程(Face Swap)
本流程介绍在 Draw Things 中进行精准人脸替换的两种主流方法,分别基于 Qwen 和 Flux 架构。
方法一:基于 qwen image edit2509
此方法利用 Qwen 模型的图像编辑能力,通过遮罩区域结合 moodboard 进行替换。
操作步骤:
1.1 导入与涂抹: 将待换脸的图片(底图)导入到画布。在画布中使用画笔工具,将底图中需要替换的面部区域涂抹为绿色。
1.2 资源放置:
画布: 放置已涂抹绿色区域的底图(图1)。
Control (Moodboard): 在 Contro…[查看更多] -
-
Draw Things:开箱即用的“苹果原生派”,专为 macOS/iOS 开发的原生 App,像 Photoshop 一样直接。界面清晰,模型下载、管理都在 App 内完成,对 16GB 内存优化极好。内置“无限画布”模式,修手、扩图操作非常直观,适合追求快速上手,想直接在 Mac 或 iPad 上高效出图的创作者。
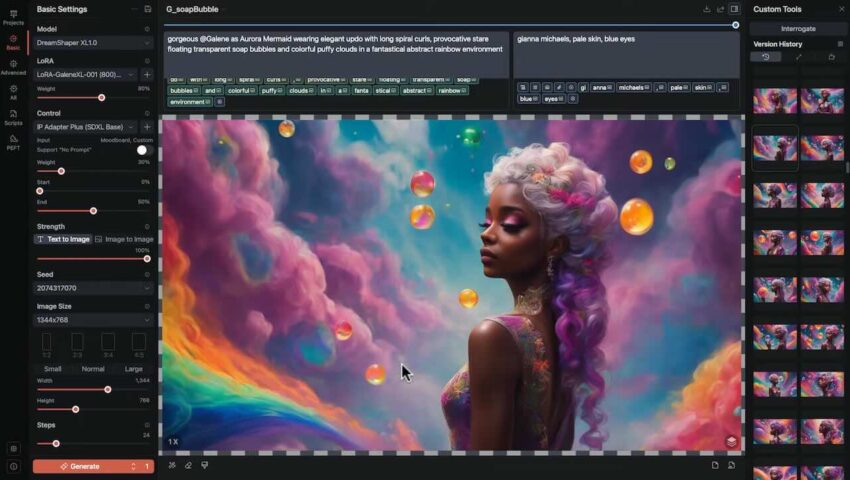
1. 核心架构与模型
Base Model: 决定画风。内存有限,请优先选择 Z Image Base (8-bit) 或 SDXL (8-bit),确保有余力加载插件。LoRA: 风格“补丁”,用于锁定特定服装(如汉服)或特定画风,权重建议 0.5-0.8。
2. 精准控制 (ControlNet):
IP-Adapter Fac…[查看更多]
-
MacBook扬声器杂音修复日志
问题描述:MacBook Pro (M1) 内置扬声器在播放音乐时出现“啪啦”、“次啦”的杂音。
交叉测试:使用耳机或外部外置声卡时声音完全正常,排除音频源和系统解码问题。初步诊断:
软件层面的核心音频进程 (coreaudiod) 出现调度错误或驱动同步异常,而非硬件损坏。解决方法:通过重置 macOS 音频核心进程解决。
操作步骤:
1. 打开 终端 (Terminal)。
2. 输入命令:
sudo killall coreaudiod
3. 输入开机密码并回车。结果:进程重启后,内置扬声器杂音消失,音频输出恢复正常。…[查看更多]
-
追光 在版块 🎞️DaVinci Resolve达芬奇调色 中回复了话题 达芬奇调色输出之后存在色差的问题【解决方法汇总】 1周, 2天 前
非常感谢分享,没想到这个帖子竟然8年了,也一直在使用苹果的设备,能发现这些区别的都是对色彩高度敏感,对品质要求极高的同行,感谢你的分享,我也学习了,好久没测试这些细节了。
-
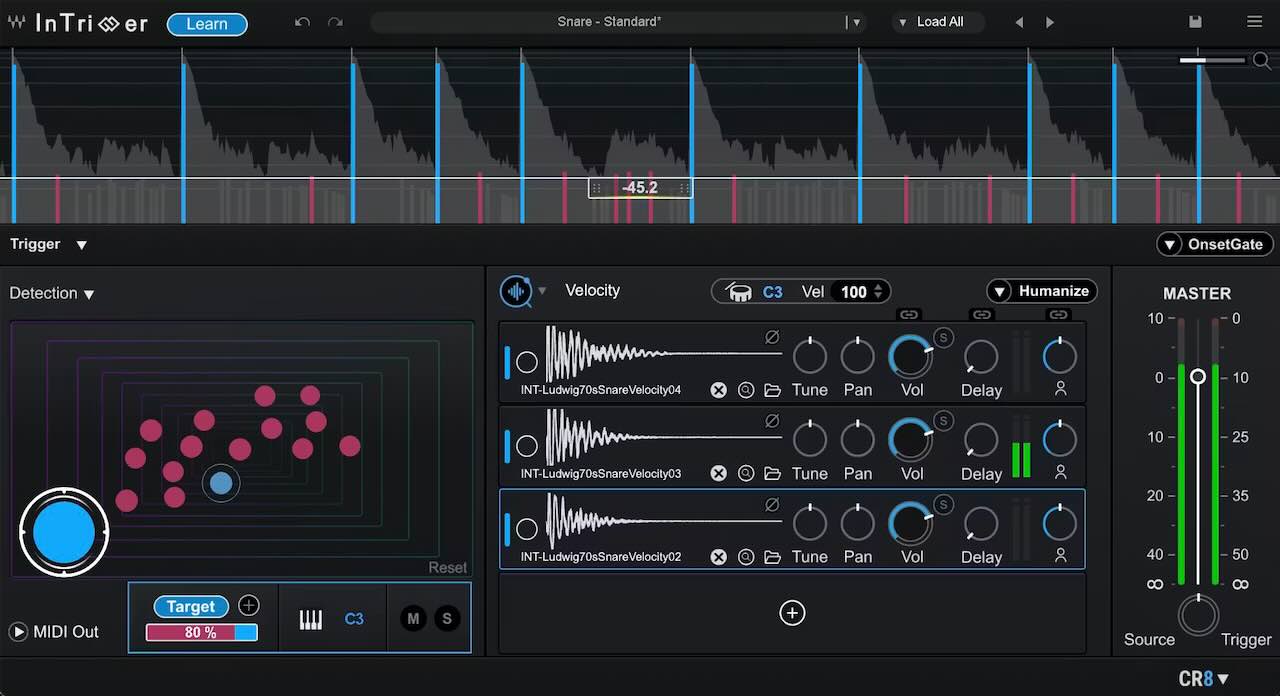
追光 在版块 Waves AI智能鼓替换插件Intrigger 鼓替换并将鼓转为Midi数据 中回复了话题 Waves AI智能鼓替换插件Intrigger 鼓替换并将鼓转为Midi数据 3周, 6天 前
在 Waves InTrigger 中,将检测到的音频打击点转换为 MIDI 数据是一个非常有用的功能,无论你是想触发外部音源(如 Superior Drummer 3 或 Kontakt),还是想保留打击动态进行后期精细编辑。
以下是将 InTrigger 识别结果录制为 MIDI 的详细操作指南:
一、插件内部设置
在将信号发送给 DAW 之前,你需要确保 InTrigger 已经正确输出了 MIDI 信号。
1. 完成检测:确保你已经通过 Learn 按钮或手动调整,让 InTrigger 准确识别了目标鼓点(蓝色线…[查看更多]
-
追光 在版块 Waves AI智能鼓替换插件Intrigger 鼓替换并将鼓转为Midi数据 中发起了话题 Waves AI智能鼓替换插件Intrigger 鼓替换并将鼓转为Midi数据 3周, 6天 前
Waves InTrigger 是一款基于 AI 技术的智能鼓组替换与补强插件,利用智能打击检测技术,能够自动识别、分类并隔离鼓点,同时过滤串音(bleed)的革命性工具。它的核心逻辑是:通过 AI 学习你原始音轨(例如底鼓或军鼓)的特征,然后精准触发干净的采样。相比传统的阈值触发器,InTrigger 极大地减少了漏触发或误触发(串音干扰)。
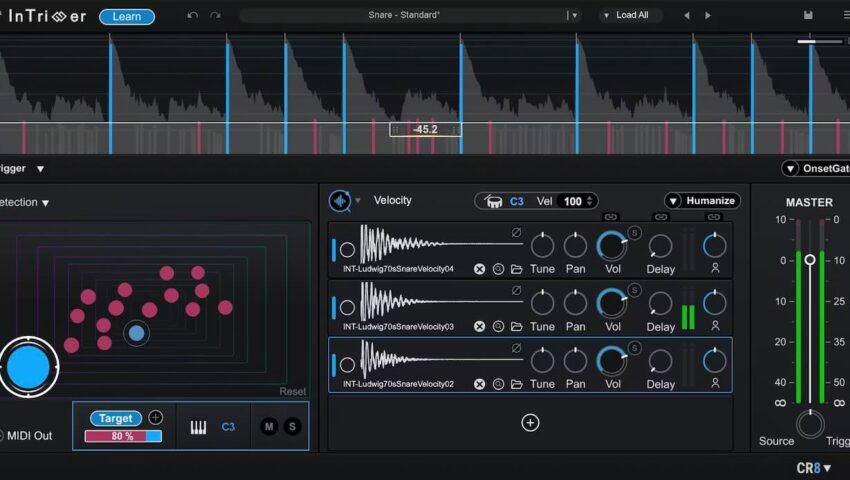
快速…[查看更多]
-
openclaw 全自动Mac安装版本脚本(粘贴到终端输入密码即可执行)
bash -c "$(cat <<'EOF'
echo "🦞 OpenClaw 一键安装启动..."# ========= 系统检测 =========
if [[ "$OSTYPE" != "darwin"* ]]; then
echo "❌ 仅支持 macOS"
exit 1
fiecho "✅ macOS 检测通过"
# ========= 网络检测 =========
echo "🌐 检测 GitHub 网络..."
if ! ping -c 1 github.com >/dev/null 2>&1; then
echo…[查看更多] - 查看更多