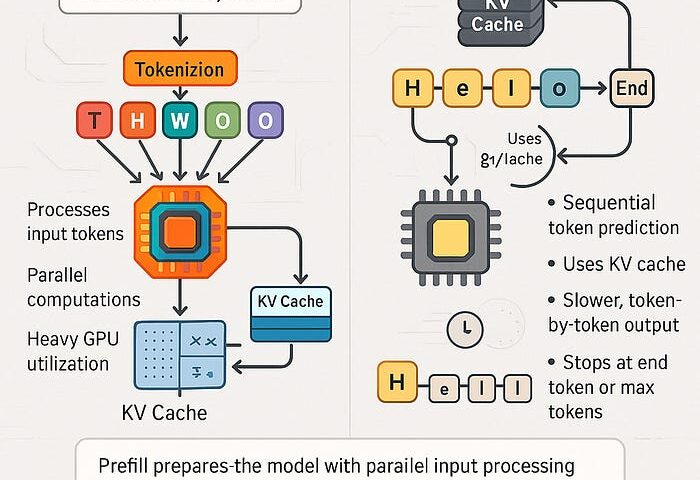
左侧的 Prefill(输入预处理)阶段: 展示了输入的 Token 提示词是如何通过大规模矩阵乘法,一次性、并行(Parallel)地灌入 GPU 算力核心中,并生成 KV Cache 存入显存。这解释了为什么“算力(Compute-Bound)”是这个阶段的瓶颈。 右侧的 Decoding(输出字生成)阶段: 展示了典型的自回归(Autoregressive)循环。模型每输出一个 Token,都需要重新流式读取大量模型权重与 KV Cache 数据参与计算。这解释了为什么“显存带宽(Memory Bound)”通常是决定本地蹦字快慢的核心瓶颈。
一、 本地推理核心参数全解析
本地推理面板上的参数主要分为两大类:计算资源调度(决定快慢与生死)与采样控制(决定生成质量)。
1. 计算资源与内存调度参数
✦ 上下文长度 (\(N_{\text{ctx}}\))
- 物理意义:大模型单次对话能够记忆并处理的最大 Token 总量(包含系统提示词、工具定义、历史对话及当前输入)。
- 性能影响:标准 Attention 的理论计算复杂度与上下文长度呈二次方级(\(O(N^2)\))增长。Flash Attention 并不会改变这一理论复杂度,但会显著减少显存访问与中间缓存开销,使长文本推理在工程实现上更高效。与此同时,上下文越长,用于存放记忆的 KV Cache 占用的显存/内存也会持续线性增长。
- 调优建议:在 16GB 内存设备上,切勿盲目开满模型宣称的 256k(如 Qwen3.5)。建议日常设为 32768 (32k) 或 64000 (64k),否则 KV Cache 会直接挤爆内存触发 Swap 导致系统死锁。
✦ GPU 卸载 (GPU Offload / Layers)
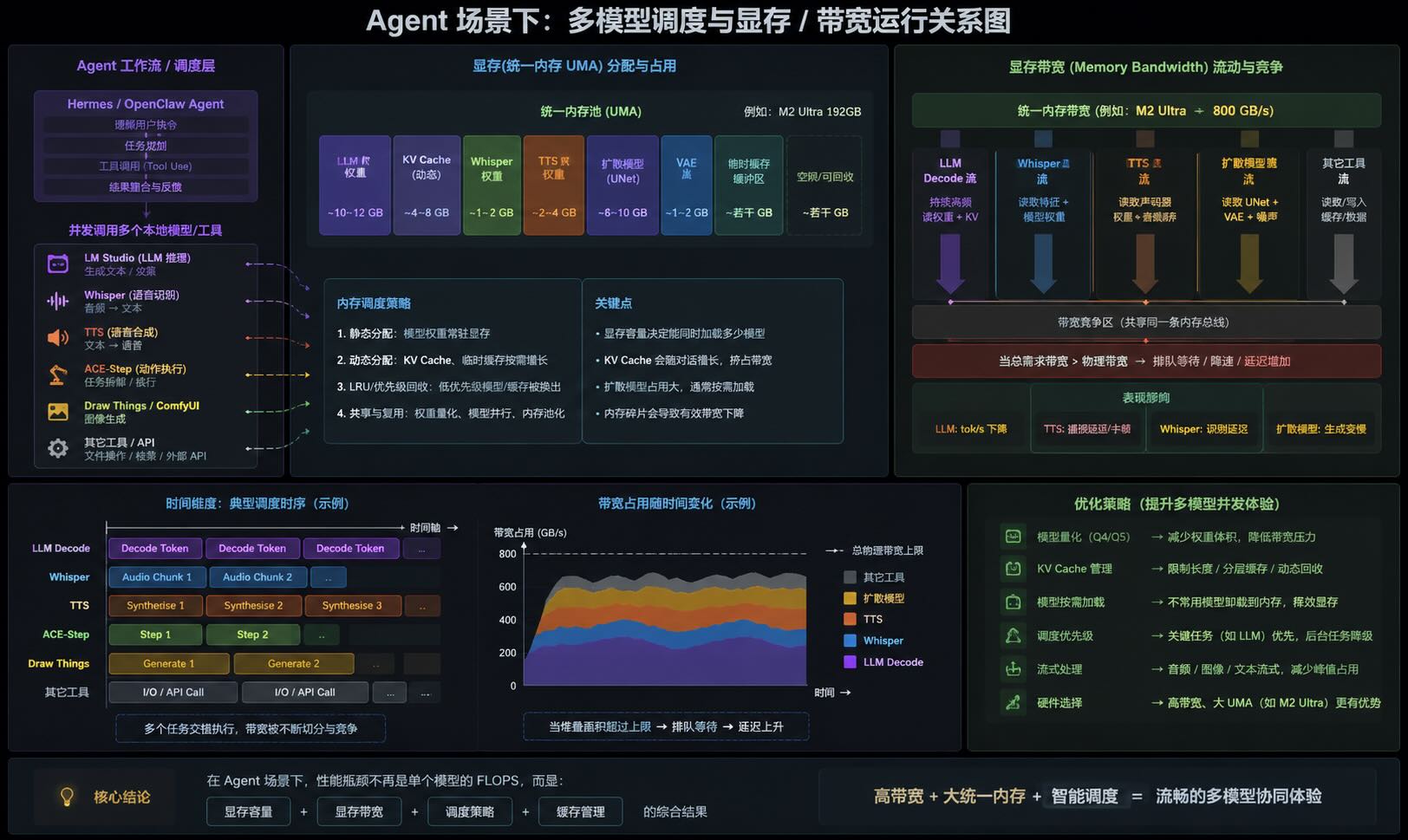
- 物理意义:大模型由数十层(Layers)复杂的神经网络堆叠而成。该参数决定将多少层网络放进 GPU 显存,多少层留给 CPU 内存。
- 性能影响:GPU 拥有极高的并行计算吞吐能力,而 CPU 带宽远低于 GPU。未卸载到 GPU 的层需要依靠 CPU 计算,并在两者之间发生高延迟的数据传输(PCIe 瓶颈)。
- 调优建议:在显存足够的独立显卡,或采用统一内存架构(UMA)的 Apple Silicon(M系列芯片)上,直接拉满至 Max (100%)。确保绝大多数矩阵计算全部流经 GPU Tensor Core。
✦ 快速注意力 (Flash Attention)
- 物理意义:一种革命性的注意力机制优化算法。通过 IO-Aware Tiling(分块计算)减少 GPU 高速缓存(SRAM)与主显存(HBM/VRAM)之间频繁读取数据的次数。
- 性能影响:对速度和显存的双重优化。在长文本场景下,能够显著降低显存占用并提升长文本吞吐速率。
- 调优建议:必须保持开启(Enabled)。
✦ K/V 缓存量化 (K/V Cache Quantization)
- 物理意义:在多轮对话中,随着上下文变长,历史 Token 计算出的键(Key)和值(Value)矩阵会一直常驻在显存中(即 KV Cache)。该参数将这些长驻矩阵从普通的 FP16(16位浮点)压缩为 Q4_0(4位)或 Q8_0(8位)。
- 性能影响:开启后,能够直接释放大量上下文显存占用,代价是长文本逻辑能力可能会出现轻微劣化。
- 调优建议:内存吃紧(如 16GB 设备跑 9B 级别模型处理大文本)时,强烈建议开启并设置为 Q4_0。
2. 采样与生成控制参数 (Sampler Settings)
✦ Temperature (温度)
- 物理意义:调整预测下一个 Token 时,词表概率分布的“平滑度”。
- 性能影响:不影响计算速度。温度越高(如 \(>1.0\)),概率低的词越容易被选中,模型表现得越有“创造力”甚至胡言乱语;温度越低(如 \(\rightarrow 0\)),模型只挑概率最高的词输出,结果极度严谨、确定。
- 调优建议:写代码、算账等严肃任务调至 0.0 ~ 0.2;文案创作调至 0.7 ~ 0.8。
✦ Top-P / Top-K (核采样与Top-K过滤)
- 物理意义:
- Top-K:限制模型只能在前 \(K\) 个最有可能的词中挑选。
- Top-P:动态保留累加概率达到 \(P\) 的词池(例如 \(P=0.9\),则只在贡献了前 \(90\%\) 概率的词中选)。
- 性能影响:在推理的收尾阶段过滤不合理的词,对底层计算开销无显著影响。
- 调优建议:标准黄金组合为 Top-P = 0.9,Top-K = 40。
二、 输入 Token 与输出 Token 在显卡上的运作原理
要彻底理解为什么本地大模型“输入慢、输出快”或者“输入快、输出慢”,必须了解大模型在显卡内部运算的两个完全不同的物理阶段:Prefill(预处理阶段) 与 Decoding(逐字生成阶段)。
1. 输入阶段(Prefill 阶段):矩阵乘法的“带宽饕餮”
当你把一大段提示词(例如 2.2W 字的长账单和巨型 Tools 定义)发送给模型时,显卡进入 Prefill 阶段。
运作原理:
- 显卡需要一次性把你输入的这几万个 Token 转换成词向量。
- GPU 拥有成千上万个计算核心(Tensor Cores),在输入阶段,这几万个 Token 可以被完全并行化拆分。GPU 的核心会被瞬间塞满,进行极其庞大的矩阵对矩阵(Matrix-Matrix, GEMM)的并行乘法计算。
- 计算完毕后,每一个输入 Token 产生的关键信息被编码,存入显存作为 KV Cache。
物理特性(Compute-Bound / 算力受限型):
在这个阶段,限制显卡速度的核心因素并不是“显存传送数据的速度”,而是“GPU 核心每秒能完成多少浮点运算(TFLOPS)”。
- 为什么有时候输入极慢?
如果提示词长达 37,321 个 Token,且 Prompt Cache(提示词缓存)未命中。GPU 必须重新完成这 37,321 个 Token 的全量 Attention 与 GEMM 计算。由于计算量极其庞大,GPU 算力达到瓶颈,就会导致前置预处理持续数十秒甚至数分钟。 - 为什么 LM Studio 体验快?
如果命中提示词缓存(Prompt Cache),GPU 就会直接复用上一次已经计算好的 Prefix KV Cache,从而跳过大部分重复计算,耗时能从数分钟缩短到数秒内。
2. 输出阶段(Decoding 阶段):单线程自回归的“带宽地狱”
当预处理结束,模型开始在屏幕上“逐字蹦字”时,显卡进入 Decoding 阶段。
运作原理:
大模型是自回归(Autoregressive)的。意思是,它无法同时生成一句话,一次只能生成一个 Token。
- GPU 把“历史所有的输入 + 已经生成的所有字”作为上下文。
- 关键之处:为了吐出这唯一一个新 Token,GPU 需要逐层执行 Transformer Forward,并持续从显存中流式读取大量模型权重与 KV Cache 数据参与计算。
- 算完这一个 Token 后,新 Token 会被加入 KV Cache,然后继续进入下一轮自回归循环。
物理特性(Memory-Bandwidth Bound / 显存带宽受限型):
在这个阶段,GPU 那些恐怖的算力核心往往无法被完全利用,它们大量时间都在等待显存中的模型数据被读取。
\(\text{Decoding 吞吐率} \approx \frac{\text{显存物理带宽 (GB/s)}}{\text{模型权重体积 (GB)}}\)
- 为什么输出速度非常恒定?
因为输出速度通常近似受限于硬件显存带宽。以统一内存的 M3/M4 芯片(带宽约 100~150 GB/s)