【AI创作】开源版 Suno-ACE-Step CPP UI本地部署与音乐制作、翻唱、改编音乐流程
› 社区话题 › 📺 VFX Pipeline | 数字创意工作流 › 【AI创作】开源版 Suno-ACE-Step CPP UI本地部署与音乐制作、翻唱、改编音乐流程

- 作者帖子
- 2026-05-08 - 19:18 #131985

追光参与者开源版 Suno · 本地 AI 音乐生成 · 一键安装,推荐使用更成熟稳定的 C++ 推理版本,其在MAC与Win系统上支持GGUF格式模型,也就意味着支持种类丰富、性能全面的模型生态,相比 MLX 版目前只有单一模型且生成质量偏弱,CPP 版本支持完整模型体系、推理稳定性更高,实际试听效果明显更好。Mac(Apple Silicon)实测在 M1 Pro 上生成 2-3 分钟音乐约 2-4 分钟,速度虽然不算快,但已经具备实用性。
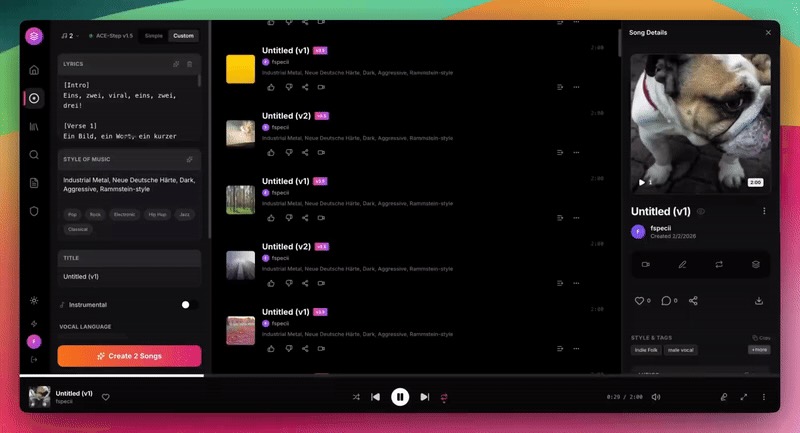 这世界有那么多人-KabuKabu吉他版cover 01 为英文j近似版 GGUF模型Cover02 为英文 创意版 GGUF模型Pink Floyd The Wall 原始曲追光Cover01创意版 Pinokia MLX模型追光 Cover02近似版 Pinokia MLX模型
这世界有那么多人-KabuKabu吉他版cover 01 为英文j近似版 GGUF模型Cover02 为英文 创意版 GGUF模型Pink Floyd The Wall 原始曲追光Cover01创意版 Pinokia MLX模型追光 Cover02近似版 Pinokia MLX模型ACE-Step CPP 本地部署详细教程。相比目前的 MLX 版本,CPP 版支持完整模型体系,音乐质量明显更高,人声和编曲稳定性也更成熟。实测在 M1 Pro 上生成 2-3 分钟音乐约 2-4 分钟,虽然速度不算快,但已经达到真正可用的程度。
第一步:下载 ACE-Step CPP UI
项目地址:acestep-cpp-ui Github 项目页,打开终端执行:git clone https://github.com/audiohacking/acestep-cpp-ui.git cd acestep-cpp-ui第二步:安装 uv(Python 环境管理)
官方推荐使用 uv 管理 Python 环境。Mac / Linux:curl -LsSf https://astral.sh/uv/install.sh | sh安装完成后重新打开终端,确认安装:
uv --version第三步:创建 Python 虚拟环境
在项目目录执行:uv venv激活环境:Mac / Linux:
source .venv/bin/activate第四步:安装 Python 依赖执行:
uv pip install -r requirements.txt等待依赖安装完成。
第五步:安装 Node.js 依赖
项目 UI 依赖 Node.js,需要先安装 Node.js:brew install node确认安装:
node -v npm -v随后在项目目录执行:
npm install第六步:下载模型
根据官方说明下载模型文件,模型目录,将下载后的模型放入:acestep-cpp-ui/models/目录结构示例:
acestep-cpp-ui/ ├── models/ │ ├── turbo │ ├── turbo-shift1 │ └── turbo-shift3Pinokia版本一键安装:这种方法适合对cli操作不熟悉的用户
下载 Pinokio(官网或 GitHub Releases)→ 安装 Mac 版 dmg 并拖入 Applications → 打开后自动初始化环境(约 2-5 分钟)→ 进入 Discover → 搜索acestep-cpp-ui→ 点击 Install → 安装完成后点 Start → 浏览器访问
http://localhost:3000使用。
pinokia版本仅仅支持mlx模型,虽然软件前端已经设计了支持所有模型,但苦于MLX社区仅仅发布了一个 ace Step turbo版本的模型,不能使用base、SFT模型。
第三步:启动与基础配置
1. 启动服务ACE-Step UI → 等待控制台输出结束
2. 访问界面
浏览器打开:http://localhost:3000
或点击 Pinokio 中的 Open 按钮直接跳转,起一个用户名即可登陆进入使用。特别提示:登陆名需要固定,每次生成的音乐会在对应的用户名下。
Ace Step 1.5 Ui 登陆界面
简单理解:高 shift 像「先画轮廓再填细节」,低 shift 像「边画边修」。
模型 蒸馏配置 特点 turbo(默认)
在 shift 1, 2, 3 上联合蒸馏 创造性与语义兼顾最佳,经过充分测试,推荐首选 turbo-shift1仅在 shift=1 上蒸馏 细节更丰富,但语义会弱一些 turbo-shift3仅在 shift=3 上蒸馏 音色更清晰丰富,但会显得「干」,配器偏极简 turbo-continuous实验性,支持 shift 1–5 连续调节 调参最灵活,但未经充分测试 - 2026-05-11 - 14:25 #132025
追光参与者ACE-Step 1.5 操作规范
一、 核心原则与架构选型
定位:以人为中心的协作式生成工具。接受随机性,采用“批量探索 → 自动初筛 → 人工精调 → 局部修正”的迭代工作流。
架构流向:用户输入 → 5Hz LM(规划器)推理元数据/优化Caption/生成语义Codes → DiT(执行器)扩散生成音频。
LM选型(规划器):显存小于8G选无或0.6B;8至16G选1.7B(默认);大于16G或复杂长尾任务选4B。模型越大,世界知识越丰富,记忆与长尾风格处理能力越强。
LLM 是核心的“指挥官”,负责将自然语言转化为音乐逻辑:
结构规划: LLM 将歌词与提示词拆解为“主歌-副歌-间奏”的音乐结构,确保整首曲目逻辑连贯。
语义对齐: 将文字描述(如“爵士乐”)映射为音频模型可理解的特征,实现指令与音频的精准同步。
律动控制: 负责歌词与节拍的精细映射,确保演唱在节律上精准且自然。
DiT选型(执行器):turbo为默认首选,创造性与语义兼顾,8步出音频;turbo-shift1重细节;turbo-shift3音色干爽极简;sft/base适用于高保真调参或特殊任务(lego/complete/extract仅限base模型)。
二、 输入控制规范
1. Caption(全局画像)
构成维度:风格 + 情绪 + 乐器 + 音色质感 + 时代参考 + 制作风格 + 人声特点 + 结构提示。
编写原则:具体优于模糊;多维度组合锚定方向;善用参考句式(如 in the style of…);使用质感词(warm, crisp, airy, punchy, lo-fi)。
禁忌:严禁在Caption中写入BPM、调性、拍号等元数据;避免冲突风格混搭,若需混搭请改为时间演变描述(开头…中段…结尾…)。
2. Lyrics(时间脚本)
结构标记:使用标记,仅保留1至2个核心词,复杂描述移至Caption。
常用结构标记:
类别 标记 说明 基础结构 [Intro]开场,建立氛围 [Verse][Verse 1]主歌,叙事推进 [Pre-Chorus]导歌,积蓄能量 [Chorus]副歌,情感高潮 [Bridge]桥段,转折或升华 [Outro]结尾,收束 动态段落 [Build]能量逐渐攀升 [Drop]电子乐的能量释放 [Breakdown]配器减少,留白 器乐段落 [Instrumental]纯器乐,无人声 [Guitar Solo]吉他独奏 [Piano Interlude]钢琴间奏 特殊标记 [Fade Out]渐弱结束 [Silence]静默 [Intro – ambient]
[Main Theme – piano]
[Climax – powerful]
[Outro – fade out]
控制标记:演唱方式如
[raspy vocal] 沙哑、有质感的人声 [whispered] 轻声细语 [falsetto] 假声 [powerful belting] 高亢有力的演唱 [spoken word] 说唱/朗诵 [harmonies] 和声层叠 [call and response] 一呼一应 [ad-lib] 即兴装饰音能量情绪如
[high energy] 高能量、激昂 [low energy] 低能量、内敛 [building energy] 能量递增 [explosive] 爆发性能量 [melancholic] 忧郁 [euphoric] 欣快 [dreamy] 梦幻 [aggressive] 激进文本规范:每行严格控制在6至10个音节,同结构位置的行音节数偏差不超过
全大写表示强力度或呐喊;
段落间必须空行
[Verse] walking through the empty streets(正常力度)[Chorus]
WE ARE THE CHAMPIONS!(高强度、呐喊)圆括号表示背景和声;
[Chorus] We rise together (together) Into the light (into the light)延长元音:可以通过重复元音来延长音:
Feeeling so aliiive纯音乐填写 [Instrumental] 或器乐结构标记
[Intro - ambient][Main Theme – piano]
[Climax – powerful]
[Outro – fade out]
避坑:禁止形容词堆砌、押韵混乱、段落越界、隐喻频繁切换。坚持单一核心隐喻贯穿全曲。
3. 元数据(Metadata)
默认策略:开启 usecotmetas=True,交由LM自动推断。
手动干预范围:bpm(30至300,稳定区间60至180);keyscale(标准调性C/G/D/Am/Em最稳);timesignature(4/4最稳,3/4与6/8可用,5/4与7/8为高级玩法);duration(30秒至4分钟,超长易结构重复)。
铁律:元数据参数值严禁与Caption或Lyrics描述冲突。
4. 音频控制与任务类型
text2music:文本驱动全局生成,无需输入音频。
cover:输入 srcaudio 进行旋律/节奏/和弦/结构迁移。通过 audiocoverstrength(0.0至1.0)控制遵循度,0.0自由发挥,1.0严格对齐。支持Remix与改词。
repaint:输入 srcaudio 进行局部修改或续写。操作区间限定3至90秒,支持无限拼接与智能缝合。
lego/complete:仅base模型支持。lego用于智能加轨,complete用于单轨混音补全。
referenceaudio:全局参考音频。系统自动截取拼接为30秒潜特征,全局控制音色、混音、演奏风格与氛围。
三、 推理参数精密配置
1. DiT(扩散模型)参数
inferencesteps:turbo固定8步;base模型建议32至100步。步数越高细节越多,速度越慢。
guidancescale:默认7.0。仅base模型有效。值越高越遵循Prompt,过高易过拟合或生硬。
shift:默认1.0。控制去噪轨迹偏移。值越大重早期结构构建,值越小重后期细节打磨。
infermethod:ode为确定性生成;sde引入随机性。
audiocoverstrength:默认1.0。控制Cover/Repaint任务中对源音频结构的遵循程度。
2. 5Hz LM(语言模型)参数
thinking:默认True。启用CoT推理,关闭则跳过LM由人工接管规划。
lmtemperature:默认0.85。值越高越具创意与随机性,值越低越保守确定。调试排查时建议降至0.7以下。
lmcfgscale:默认2.0。控制LM对正向Prompt的遵循强度。
lmtopp / lmtopk:默认0.9 / 0。Top-K为0表示禁用核采样限制。
usecotcaption / usecotmetas:默认均为True。自动优化Caption描述并推理元数据。
lmnegativeprompt:默认 NO USER INPUT。用于告知LM需规避的方向。
四、 标准工作流 (SOP)
第一步:意图设定。编写Caption与Lyrics,选择tasktype,按需上传referenceaudio或srcaudio。
第二步:批量探索。设置 batchsize 为4至8,开启 AutoGen 后台持续生成,使用随机Seed探索创意空间。
第三步:自动初筛。启用自动打分机制,优先依据 DiT Lyrics Alignment Score(词曲对齐度)过滤低质结果。
第四步:人工精调。锁定满意结果的Seed,微调 lmtemperature、shift 或 audiocoverstrength 进行变体抽卡;修正Lyrics音节或冲突标记。
第五步:局部修正。针对瑕疵段落使用 repaint 划定3至90秒区间重生成,或调整Cover强度优化结构。
第六步:工程输出。确认结构、音色、对齐度达标后,导出分轨或完整音频。
五、 边界控制与核心心法
指令冲突排查:Caption与Lyrics的乐器/情绪必须一致;元数据交由参数控制,Caption专注风格与音色。
标记过载防范:结构标记精简至1至2词,复杂描述一律移至Caption,防止模型将标记误唱或逻辑混乱。
节奏断裂修复:严格对齐每行6至10音节,同结构行保持正负2偏差,避免节奏怪异。
控制边界认知:文本是降维抽象,无法精确控制每个音符或混音细节。需接受模型随机性,改用 referenceaudio 或 srcaudio 进行声学级控制。
歌词去AI化:坚持单一核心隐喻,控制行长度,避免空洞形容词串联与押韵硬凑,保留呼吸感。
操作心法:将随机性视为探索工具而非缺陷。用固定Seed做参数归因调试,用随机Seed做创意挖掘。快速迭代优于单次完美,保持心流节奏。文本定方向,音频控细节,批量出结果,人工做取舍。
- 2026-05-11 - 17:16 #132042
追光参与者ACE-Step 1.5 的 Cover(翻唱)精密工作流
一、 Cover(翻唱/结构迁移)精密工作流
核心原理 将源音频量化为语义结构化信息(旋律、节奏、和弦、配器),在新 Caption 与 Lyrics 的驱动下重新演绎。源音频提供骨架,文本提供血肉与风格。
输入与参数配置
任务类型:task_type 设为 cover
音频输入:上传 src_audio(需结构清晰、无严重底噪)
需要在翻唱位置插入音频,这里插入的音频作为src_audio
文本输入:填写新 caption 与 lyrics(可改风格、改情绪、改歌词)
核心参数:audio_cover_strength(0.0 至 1.0)。1.0 严格对齐原曲结构,0.0 完全自由发挥。日常推荐 0.6 至 0.8。
LM 设置:建议关闭 thinking 模式。源音频已约束作曲与结构,人工直接接管规划,跳过 LM 推理可显著提升速度并避免意图冲突。
Pink Floyd The Wall 原始曲追光Cover01创意版 Pinokia MLX模型追光 Cover02近似版 Pinokia MLX模型标准操作步骤
1、素材准备
选取结构完整的源音频,编写目标风格的 Caption 与 Lyrics。确保文本描述与原曲节奏骨架不冲突。
2、参数装载
设置 task_type=cover,上传 src_audio,填入新文本。将 audio_cover_strength 设为 0.7 作为起点。
3、批量探索
关闭 thinking,设置 batch_size=4 至 8,开启 AutoGen 与随机 Seed。让 DiT 在固定结构下探索不同演绎。
4、自动初筛
启用自动打分,优先依据 DiT Lyrics Alignment Score 过滤词曲对齐度低的版本。
5、人工精调
锁定满意结果的 Seed。若结构偏移过大,调高 cover_strength;若演绎死板,调低强度或微调 lm_temperature(若开启 LM)。
6、定型输出
确认旋律走向、歌词咬字、风格融合度达标后,导出音频。如需多版本对比,固定 Seed 仅调整强度参数进行 Retake 抽卡。
Caption 聚焦目标风格与声学特征示例:
cyberpunk electronic rock, distorted synth bass, aggressive drum machine, dark atmospheric, male gritty vocal, studio-polished Lyrics 按原曲段落结构重写,严格保持每行6至10音节,同位置行偏差不超过2。结构标记仅保留1至2词,如 [Verse] [Chorus]。
高级玩法 Remix 重构:保留原曲和弦与节奏,通过改写 Caption 实现跨风格迁移(如流行转摇滚),或重写 Lyrics 实现改词翻唱。 复杂结构构建:利用 cover_strength 的梯度变化(如主歌 0.8、副歌 0.5)在同一首歌中实现结构遵循度的动态控制。 Retake 抽卡:固定 src_audio 与文本,仅更换 Seed 批量生成,快速获取同一结构下的不同演唱/配器变体。
关键避坑:源音频质量决定上限。严重压缩、人声伴奏粘连或节奏混乱的音频会导致结构提取失真。 强度参数勿走极端。1.0 易导致机械复制、丧失新风格特征;低于 0.4 易丢失原曲骨架,退化为 text2music。 文本与结构需对齐。若原曲为慢板抒情,但 Lyrics 填入高密度快嘴说唱,模型会产生节奏撕裂。请保持音节密度与原曲律动匹配。
- 2026-05-11 - 17:16 #132043
追光参与者二、 Repaint(局部重绘/续写)精密工作流
核心原理 基于源音频的上下文进行区间补全或修改。模型读取划定区间的前后文潜特征,在指定时间内重新生成,自动处理节奏、和声与音色的衔接。
输入与参数配置
任务类型:task_type 设为 repaint
音频输入:上传 src_audio(需包含完整上下文)
需要在翻唱位置插入音频,这里插入的音频作为src_audio
区间控制:设置 repainting_start 与 repainting_end。操作范围严格限制在 3 秒至 90 秒。
核心参数:audio_cover_strength 控制上下文遵循度。改词/改结构建议 0.5 至 0.7;纯修复/续写建议 0.8 至 1.0。
LM 设置:开启或关闭均可。Repaint 侧重局部细节与上下文衔接,DiT 直接基于音频上下文工作,LM 仅辅助文本规划。
标准操作步骤
1、定位区间
在源音频中精确定位需修改或续写的起点与终点。确保区间长度在 3 至 90 秒之间,且前后保留至少 2 秒完整上下文。
2、参数装载
设置 task_type=repaint,上传 src_audio,填入区间参数。若需改词或改结构,同步更新对应区间的 Lyrics 标记。
3、上下文生成
保持 batch_size=4 至 6,开启 AutoGen。模型将参考前后文在划定区间内重新雕刻音频。
4、衔接听辨
重点听辨区间边界处的节奏对齐、和声过渡与音色融合。若出现断层或突兀,微调区间边界(前后移动 0.5 至 1 秒)重绘。
5、迭代锁定
满意后锁定 Seed。若需调整局部演唱力度或配器层次,微调 cover_strength 或 Lyrics 控制标记(如 [powerful]、[whispered])重新生成。
6、拼接导出
确认局部与全局无缝融合后导出。若需继续延伸,将新生成音频作为下一轮 src_audio,重复上述流程。
高级玩法
限时长生成:通过多次 Repaint 首尾相接,每次续写 30 至 60 秒。基于前段上下文保持音乐自然过渡,突破单次生成时长限制。
智能音频缝合:将两段独立音频拼接,在连接处划定 5 至 15 秒区间使用 Repaint。模型会自动补全过渡段,实现节奏/和声/音色的平滑融合。
局部克隆与修复:保留源音频整体混音与人声特质,仅针对瑕疵段落(如破音、配器冲突、歌词咬字不清)进行定点重绘,不破坏全局一致性。
关键避坑
区间严禁越界,短于 3 秒上下文不足,生成易断裂;长于 90 秒模型注意力分散,易出现结构重复或逻辑漂移。
Lyrics 音节需匹配原节奏。重绘区间的歌词音节数应与原曲对应位置的节拍数保持 ±2 偏差,否则会导致节奏错位或拖拍/抢拍。 边界微调优于参数硬拉。衔接不自然时,优先移动 repainting_start/end 边界 0.5 至 1 秒,而非盲目调整 cover_strength。
上下文窗口的微小变化对缝合质量影响远大于参数。
避免连续重绘叠加失真。同一区间反复 Repaint 超过 3 次可能导致高频细节丢失或底噪累积。
建议回退至上一步满意版本,调整区间或文本后重新生成。
固定 Seed 做参数归因,随机 Seed 做创意挖掘。 接受模型惯性,引导而非强控。将随机性视为探索工具,快速迭代优于单次完美。保持心流节奏,让工作流服务于创作直觉。
- 2026-05-11 - 18:30 #132057
追光参与者参考音频(referenceaudio)
控制「听起来像什么」:音色、混音、演奏风格、整体氛围。
后台用 VAE 编码为 latents,平均时间信息,全局作用,不保留具体旋律结构。源音频(srcaudio)
控制「结构是什么样」:旋律走向、节奏、和弦、配器层次。
用于 Cover 任务,量化为语义 codes,可通过 audiocoverstrength(0~1)调节结构遵循程度。🔹 一句话区分:参考音频管质感,源音频管骨架。
[Intro - piano] [Verse 1] 月光洒在窗台上 我听见你的呼吸 城市在远处沉睡 只有我们还醒着 [Pre-Chorus] 这一刻如此安静 却藏着汹涌的心 [Chorus - powerful] 让我们燃烧吧 像夜空中的烟火 短暂却绚烂 这就是我们的时刻 [Verse 2] 时间在指尖流过 我们抓不住什么 但至少此刻拥有 彼此眼中的火焰 [Bridge - whispered] 如果明天一切消散 至少我们曾经闪耀 [Final Chorus] 让我们燃烧吧 像夜空中的烟火 短暂却绚烂 THIS IS OUR MOMENT! [Outro - fade out] - 2026-05-13 - 16:25 #132079
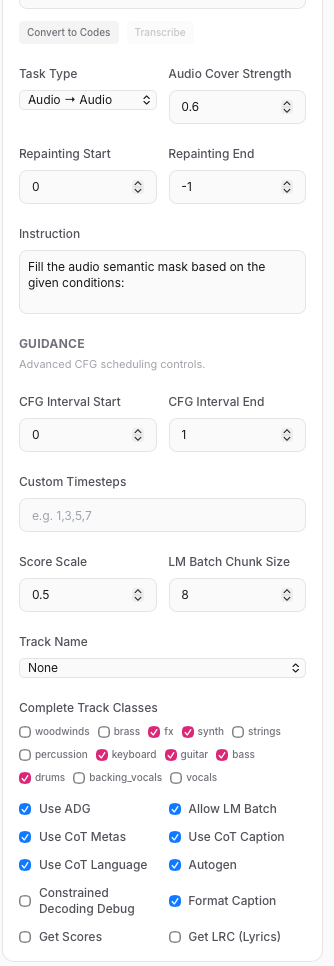
追光参与者针对 ACE-Step 1.5 界面(UI)的 Audio-to-Audio 编曲补全(Complete) 模式,操作指南如下:
1. 核心模式选择
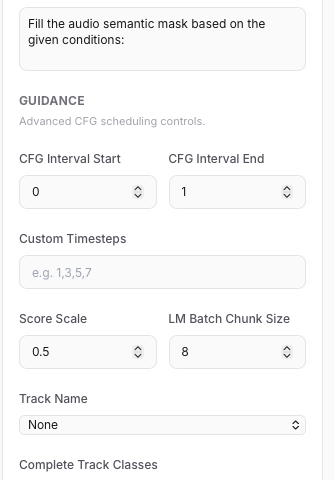
Task Type:必须选择 Audio → Audio。
Instruction:确认框内显示 Fill the audio semantic mask…,这代表系统已进入补全逻辑。2. 关键参数设置(解决“难听”问题)
Audio Cover Strength:建议调低至 0.3 – 0.4。 注:数值越低,越能完整保留你的原始人声;过高会导致人声扭曲产生噪音。
Complete Track Classes:精准勾选。建议仅勾选 drums(鼓)、bass(贝斯)、guitar(吉他),避免音轨过多导致频谱混乱。
Repainting Start/End:保持默认的 0 和 -1,表示对整段音频进行编曲补全。3. 高级引导设置
Use CoT (Metas/Caption):全部勾选(蓝色打钩状态)。这会让 AI 先通过 LLM 思考编曲逻辑,生成的背景乐更具旋律感。
Score Scale:保持 0.5 左右。如果伴奏太吵,可微调至 0.3。
CFG Interval End:建议设为 0.8。在生成后期减少人工引导,能显著降低金属乐的数字毛刺感。4. 提交与检查
- 2026-05-13 - 16:36 #132083
追光参与者ACE-STEP-API-SKILL.md 和实际操作日志,以下是使用 API 提交任务的标准格式教程,涵盖了常用的处理模式:
1. 认证准备 (Token 获取)
在进行任何 API 调用前,必须先获取临时授权 Token:TOKEN=$(curl -sS http://127.0.0.1:3001/api/auth/auto | sed -n 's/.*"token":"\([^"]*\)".*/\1/p')2. 标准提交格式 (包含不同模式配置)
所有的提交均通过 POST http://127.0.0.1:3001/api/generate 接口完成。
模式 A:编曲补全模式 (Complete) —— 针对清唱加伴奏
这是你最需要的模式,核心在于锁定人声并填充背景:{ "taskType": "complete", "sourceAudioPath": "/路径/到/你的/vocals.wav", "songDescription": "symphonic metal, power drums, electric guitar riffs", "completeTrackClasses": ["drums", "bass", "guitar"], "audioCoverStrength": 0.35, "thinking": true, "inferenceSteps": 12 }模式 B:风格转换模式 (Cover) —— 改变音色/翻唱
用于将一段音频转换成另一种演唱风格:{ "taskType": "cover", "sourceAudioPath": "/路径/到/源音频.wav", "songDescription": "opera style, female soprano, high quality", "audioCoverStrength": 0.6, "thinking": false }模式 C:文生音乐模式 (Text-to-Music) —— 纯创作
直接根据文字描述生成 30 秒音乐:{ "taskType": "text2music", "songDescription": "lo-fi hip hop, chill vibes, rainy day", "duration": 30, "instrumental": true, "inferenceSteps": 8 }3. 关键参数详解
• audioCoverStrength: 补全模式建议 0.3-0.4(保护原声);转换模式建议 0.5-0.7(允许重绘)。
• completeTrackClasses: 数组格式,可选:drums, bass, guitar, piano, synth, strings 等。
• thinking: 设为 true 会调用 LLM 进行 CoT 思考,显著提升音乐逻辑感。
• inferenceSteps: 默认 8 步,若追求高保真补全建议设为 12-15。4. 任务追踪与获取结果
提交后会返回 jobId,使用以下命令查询状态:curl -sS "http://127.0.0.1:3001/api/generate/status/:jobId" -H "Authorization: Bearer $TOKEN"当状态从 running 变为 succeeded 时,返回结果中会包含生成的音频下载地址。
curl -sS -X POST http://127.0.0.1:3001/api/generate \ -H "Content-Type: application/json" \ -H "Authorization: Bearer $TOKEN" \ -d '{ "taskType": "complete", "sourceAudioPath": "/Users/xbaby/Downloads/vocals.wav", "songDescription": "symphonic metal, power drums, electric guitar accompaniment, 120bpm", "completeTrackClasses": ["drums", "bass", "guitar"], "audioCoverStrength": 0.32, "inferenceSteps": 12, "guidanceScale": 4.5, "thinking": true }' - 2026-05-24 - 10:20 #132278
追光参与者pinokia版本的Ace step Ui在实践中的吞字问题,和无法使用添加乐器、编曲功能
目前在 Mac 的 MLX 生态中,官方及社区仅推出了 Turbo 这一款加速版模型。虽然它能8步就能出歌,但因为砍掉了语言模型(LM)的对齐逻辑,导致它有着极易“吞字、漏字”的顽疾,且在 MLX 下无法使用 Base 和 SFT 版本。不能使用 MLX 的其他版本(Base/SFT),最核心的原因并不是 Mac 硬件不支持,也不是Ace Step Ui不支持而是开源社区压根就没有做出这些格式的模型文件。
如果想在Mac上解锁 ACE-Step 1.5 的完整实力,强烈建议转向基于 GGUF 格式的 C++ 生态(如 acestep-cpp-ui):
功能全开:完美支持 GGUF 格式的 SFT(对齐微调版)、Base(基础版) 以及社区魔改的 XL 混血模型,彻底根治吞字、破音问题。
极度轻量:支持 Metal 硬件加速。选择 Q4KM 级别量化,整套系统运行仅吃 6~8GB 内存,在 12GB 的 Mac 上不仅流畅,还能免去配置 Python 虚拟环境的痛苦。
- 2026-05-27 - 20:33 #132366
追光参与者这些参数是控制acestep.cpp(Turbo 模型) AI 音乐生成效果的核心“旋钮”。下面拆解这些参数的物理含义和调整建议。
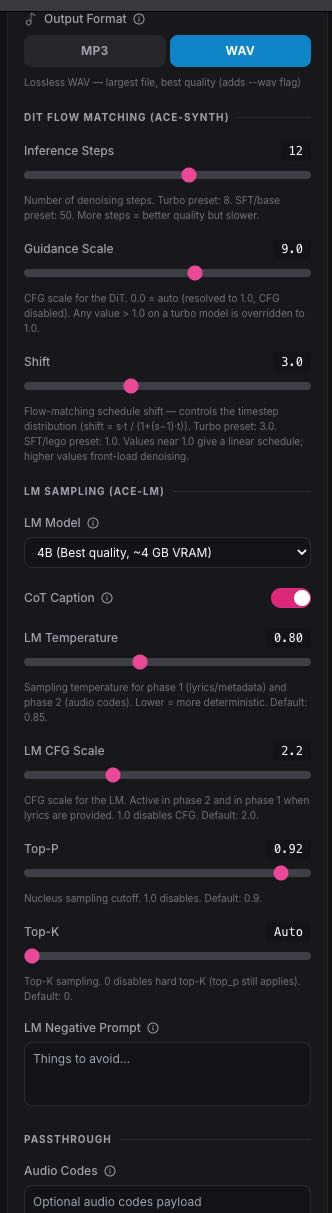
Screenshot
一、 DIT FLOW MATCHING (DiT 扩散模型参数)
这是决定“声音质量”的引擎。
Inference Steps (推理步数)
意义:扩散模型去噪的次数。步数越多,细节越细腻,但越耗时。
Turbo 模型建议:官方预设是 8,你设为 12 是合理的,能稍微增加一点稳定性。不需要过高,否则反而可能产生噪音。Guidance Scale (CFG – 引导强度)
意义:模型服从提示词(Prompt)的程度。
注意:界面显示 9.0,但你在之前的日志中看到过警告。因为 Turbo 模型已经“内化”了引导,数值高于 1.0 可能会导致音频失真或产生“金属感”。强烈建议降至 1.0 – 2.0 之间测试。Shift (流匹配偏移)
意义:控制扩散过程中的采样分布。数值越大,采样越集中在去噪的“早期阶段”。
建议:Turbo 模型预设 3.0 是经过优化的最优值,不需要频繁改动。二、 LM SAMPLING (语言模型参数)
这是决定“音乐结构、歌词、风格逻辑”的大脑。
LM Model
意义:选择核心逻辑模型的大小。4B 代表模型拥有 40 亿参数,逻辑推理更强,音乐结构的编排更合理。CoT Caption (思维链描述)
意义:开启后,AI 会先对自己要生成的音频写一段“自我描述”(Chain of Thought),以此指导生成,效果更好。建议保持开启。LM Temperature (采样温度)
意义:控制生成的随机性。
0.1 – 0.5:非常死板,适合想要完全忠实于指令。
0.7 – 0.9:创造力平衡点,默认 0.8 很合适。
1.0:可能会开始产生混乱或听不懂的乱码。LM CFG Scale
意义:语言模型层面的引导强度。这与 DiT 引导不同,它控制的是歌词和结构逻辑的连贯性。保持 2.0 – 2.5 即可。Top-P / Top-K
意义:采样过滤器,防止 AI 选择概率极低的词汇(即防止胡言乱语)。
Top-P (0.92):保留累积概率达到 92% 的词,通常默认值效果最好。
Top-K (Auto):直接限制候选词的数量。Auto 模式让模型自己根据词汇分布决定,最稳妥。三、 调整建议(实操建议)
如果你觉得目前生成的音乐“听起来不够自然”或“有杂音”,尝试以下步骤:
1. 首要调整: 将 Guidance Scale 从 9.0 降到 1.0 或 2.0。这是你目前设置中最可能导致失真的地方。
2. 次要调整: 如果音乐逻辑混乱,微调 LM Temperature(降到 0.7)。
3. 速度测试: 如果生成太慢,将 Inference Steps 从 12 降回 8,对比音质损失是否在可接受范围内。进一步建议:官方文档通常会强调 “Shift” 和 “Inference Steps” 的协同效应。在 Turbo 模型中,低步数配合高 Shift 值是为了实现“快速且高质量”的生成。
- 作者帖子

- 在下方一键注册,登录后就可以回复啦。