Activity
表里如一,知行合一,能量因此觉醒

-

一套“跨模型通用抠图/分离编辑 Prompt”(适配:Qwen Image Edit / FLUX / SDXL / 以及大多数图像编辑模型)。核心思路是:不依赖模型特性、用“约束 + 结构化语义”、避免模型各自乱发挥
🧴 1. 产品抠图(通用工业级)
Prompt
Edit the image to isolate the product as the only subject. Keep the product centered. Remove all background elements completely. Clean studio lighting. Sharp focus. Preserve all fine details and rea…[查看更多] -
今天测试了 Qwen Image Edit 2509/2511的换脸方法
新的流程是:首先将原图放在画布上,把需要替换的人脸作为第二张图放入创意板。直接用提示词替换通常会失败,因为模型会强行保持原图人脸一致性。因此关键步骤是“消除原脸干扰”。具体做法是在画布中使用画笔工具(不是橡皮),将原图人脸区域涂成实心颜色,例如绿色或棕色。 -
最近我一直在想,如果一个影视剧中用到多个角色、能不能把角色制作成Lora,这样角色就能迁移、需要几个角色、只需要调用对应的ora组合就可以。想让AI 生成的各种场景中保持脸部、妆容一致,这就需要用到训练自己的ai Lora,通过 Draw Things 就能在本地训练属于自己的 LoRA 模型,当然也可以通过Comfyui等工具来训练。本文将基于最新的 FLUX.2/SD 架构界面,训练自己的AI 角色Lora。
训练AI 角色Lora操作方法
1. 准备数据集 (Dataset)
在界面的右侧 Dataset 区域:
添加图片: 点击 “Add” 按钮,上传 15-25 张…[查看更多]
-

在 AI 绘画进入 Flux 时代后,用户对图像构图的自由度有了更高要求。flux-outpaint-lora.safetensors 便是为此而生的核心插件,它专攻 Outpainting(向外扩图/扩展填充) 领域,旨在帮助用户在不破坏原图核心逻辑的前提下,完美补全画面之外的世界。
无缝内容补全 (Seamless Integration)
该 LoRA 经过海量“原图-扩展图”对的训 […]

-
在 Qwen 开源图像编辑生态中,qwen-edit-enhance64-v3.safetensors 扮演着不可或缺的“画质炼金术士”角色。这款基于 64 维度(Rank 64) 训练的 LoRA 模型,是专门为解决 AI 生成图像中的模糊、噪点及纹理缺失而设计的进阶增强工具。
核心能力解析
1. 极速去模糊与锐化 (Deblur & Sharpening)
该模型的核心使命是修复失焦或像素化 […]

-
这款 F2P (Face to Portrait) LoRA 是专为 Qwen Image Edit(通义千问图像编辑模型)量身定制的顶级人像插件,由 Dent Studio 基于万余张高审美、高质量的人像数据精炼而成。它的核心逻辑并非简单的“AI 换脸”,而是通过强大的特征提取能力,实现从单 […]

-
这套方法的精髓在于利用 Qwen Image Edit 的局部编辑能力,配合 F2P (Face to Portrait) LoRA,实现从单一“脸部照片”到“全身/多风格肖像”的高保真转换。
一、 环境与资源准备
1. 基础模型:选择 Qwen Image Edit(基于通义千问的图像编辑模型)。
2. LoRA:加载 F2P LoRA(由 ModelScope 社区 Dent Studio 提供,基于一万多张高质量人像训练,兼顾特征一致性与人体审美)。
3. 软件工具:推荐使用 Draw Things 进行本地部署与操作。
二、 基础操作流程
-
在 QIE-2511 AnyPose 工作流中,AnyPose LoRA 并不是一个独立使用的组件,而是必须依附于主模型 Qwen Image Edit 2511 才能发挥作用。整个系统的关键在于:主模型负责“理解与重建图像”,而 LoRA 负责“控制人体结构变化”,两者是典型 […]

-
使用SD ControlNet pose精准控制AI表情、手指与姿势:进阶工作流
第一步:提取完整骨架(含脸/手)
访问「哩布哩布AI」网站,上传参考图。ControlNet 类型选 OpenPose,预处理器务必选择 OpenPose Full。系统将输出包含身体坐标、手指关键点与面部五官点位的完整骨架图。这是实现同步控制的数据基础。第二步:导入 DrawThings 图层
将生成的骨架图拖入 DT 的 Pose 图层,或放入draw thi…[查看更多] -
很多人用 AI 画图,最大的痛点根本不是不会写提示词,而是“人物姿势总乱变”。同样输入“一个站立的人”,AI 可能随机生成几十种完全不同的姿态。做分镜、角色设计或视觉预演时,这种不确定性非常致命。
解决这个问题的核心工具就是 Pose ControlNet。它的作用很直接:把“人物怎么动”从 AI 的随机发挥中抽离出来,变成你可以完全掌控的固定框架。
下面以 DrawThings 为例,走一遍最清晰、最稳定的按照我们的预期动作生成图片的操作流程。文末附你提供的完整参数配置对照表,ComfyUI 用户可直接按相同数值平移。
-
在当今数字音乐制作和内容创作日益普及的背景下,音频处理技术也在不断进步,其中人声分离技术尤为受到关注。Vocal Remover(人声去除/提取)工具中,一个被广泛使用且评价颇高的软件是 Ultimate Vocal Remover(简称 UVR)。它是一款基于深度学习的开源音频分离工具,能够将一首完整的歌曲拆解为 […]
-
在最新的 AI 图像编辑领域,QIE-2511 AnyPose 提供了一种新的姿态迁移思路:不再依赖 OpenPose 骨架提取,而是直接通过图像理解实现动作迁移。该方法基于 Qwen Image Edit 2511,并结合 AnyPose LoRA,实现仅通过参考图片即可驱动人物动作变化。

一、核心思路
传统姿态迁移依赖 OpenPose 先提取人体骨架,再将骨架作为控制信号生成图像。这种方式结构稳定,但表达能力有限。
AnyPose 的核心变化是:直接使用“图像”作为姿态信号,由模型自行理解动作结构。也就是说,模型不再依赖显式骨架,而是通过视觉理解完成隐式姿态建模,使动作更加自然灵活。
二、模型…[查看更多]
-
追光 在版块 💻 Nuke合成影视制作 中发起了话题 CorridorKey:AI 如何重新定义绿幕抠像【AI制作】 2天, 8小时 前
在影视后期制作中,绿幕抠像一直是最基础却也最耗时的环节之一。无论是使用 Keylight、Primatte,还是各种 AI roto 工具,行业的核心问题始终没有真正解决:当主体边缘与绿幕发生颜色混合时,如何准确地还原真实前景。
传统方法的思路是“分离”——通过颜色判断生成 Alpha 遮罩,再配合 edge refine、despill、roto 等流程不断修补细节。然而这种方式本质上是在做二值或半连续的分类,它很难处理头发、运动模糊、半透明材质等复杂情况,最终往往需要大量人工干预。
CorridorKey 的出现,提出了一个完全不同的思路:不再去判断“哪里是前景”,而是直接重建“前景本身”。
它的核心能力在于对图像进行“反混合”(unmixing)。在绿幕拍摄…[查看更多]
-
Pinokio 是一个面向开发者与创作者的本地化 AI 应用运行平台,主打“跨平台 + 一键部署”的极简体验。无论是在 macOS、Windows 还是 Linux 上,用户都可以通过统一的界面快速安装、启动并管理各类开源 AI 应用,无需繁琐的环境配置或依赖处理,Pinokio 把 AI 创作从“工程问题”变成“内容问题”,让你专注在创意,而不是环 […]
-
QwenVoice 是一款专为 macOS 打造的原生应用,基于 Qwen3-TTS 技术,实现高质量文本转语音(TTS)。它最大的特点是 100% 本地运行,无需联网、无 API 成本,专为 Apple Silicon 芯片优化,带来高效、安全且私密的语音生成体验。
一、核心特点
🎙 完整的离线语音工作室
QwenVoice 不只是一个简单的语音生成工具,而是一整套本地语音创作解决方案,包 […]
-
随着生成式图像技术的发展,图像编辑正在从“工具操作”转向“语言驱动”,Qwen Image Edit、Fluxkelein2等模型正是这一趋势下的代表模型。它可以在本地(如 Draw Things)运行,通过简单的提示词完成复杂的图像生成与编辑任务。在许多场景中,它已经可以替代传统依赖 LoRA 或复杂流程的工作方式。
本文将系统梳理 Qwen Image Edit 的核心能力与实际应用场景。
一、人物一致性与多场景生成
Qwen Image Edit 可以基于一张人物基础图,生成该角色在不同场景下的表现,同时保持人物外观的一致性。
例如,同一个人物可以被快…[查看更多]
-
最近在设计圈和社交媒体上,两种视觉风格非常火:霓虹玻璃面板社交名片,玻璃棱镜光谱 Logo,它们的共同特点是:未来感强、信息清晰、视觉高级。这篇教程将手把手教你,用 Qwen Image + Draw Things 实现这两种效果,而且是稳定、可控、可定制的专业流程。这里流程中使用的模型主要有俩种生图模型、图片编辑模型、可以使用qwen 模型也可以使用flux2、z image或者其他你喜欢的模型来制作。主要展示流程和提示词写。

一、核心方法思路(一定要先理解)
很多人会尝试“一步生成”,但效果往往:文字崩坏,排版混乱,不可控。
👉 正确方法是:…[查看更多]
-
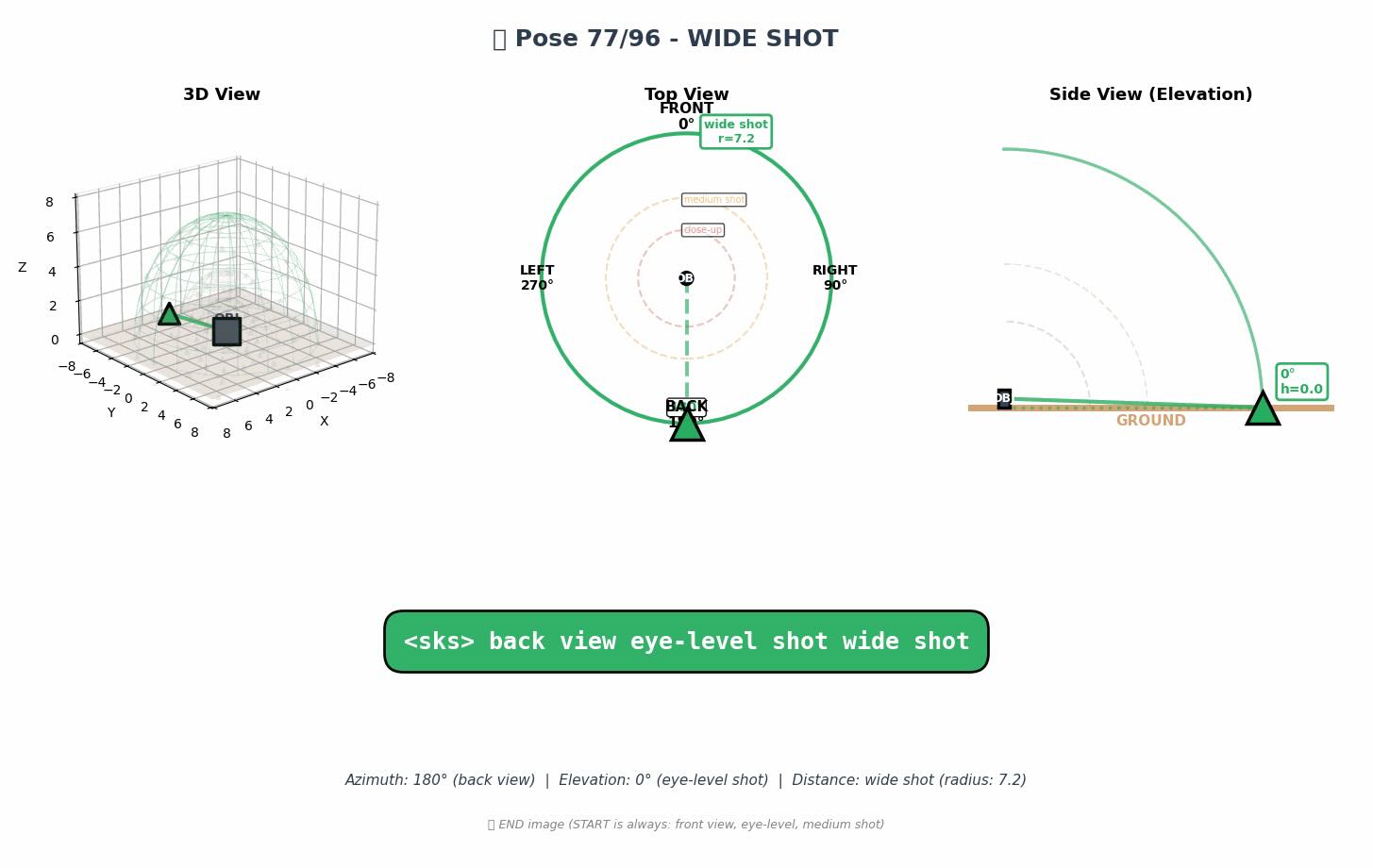
为了精准控制AI出图视角,我把 Qwen-Image-Edit-2511-Multiple-Angles-LoRA 的所有官方参数组合做成了结构化提示词库。8大方位 × 4种仰角 × 3种景别 = 96组标准写法,已按「正面/45°/侧面/背面」分段整理,每组自带使用场景备注,画角色卡、商业图,影视、游戏场景设计。
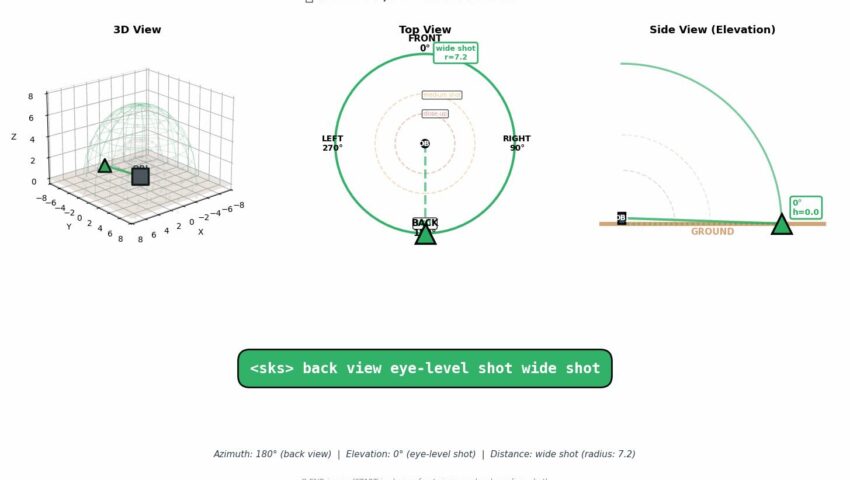
🔹 核心语法: [方位] [仰角] [景别](严格空格分隔,禁加标点/括号) 🔹 适用底模:Qwen/Qwen-Image-Edit-2511/2509 🔹 参数建议:LoRA强度 0.85~1.0,固定 Seed 可稳定生成角色三/四视图
该提示词可以在Comfyui和Draw things等调用支持Qwen image edit(1.0版本、2509…[查看更多]
-
谢谢通俗易懂
-
六、Draw Things物体移除功能(Object Removal)流程
本工作流利用 Flux Fill 强大的图像填充能力结合专用 LoRA,实现对画面中多余物体的无痕移除与背景补全。
1. 核心模型配置
主模型: flux1filldevq8p.ckpt
专用 LoRA: Object Removal Flux Fill v2(JSON 中对应文件为 fluxoutpaintloraloraf16.ckpt)
LoRA 触发提示词: Fill the green spaces according to the image,2. 操作步骤
1. 图片导入: 将包含想要移除物体的图片…[查看更多]
- 查看更多