用 Pose ControlNet 精准控图:标准工作流(DrawThings / ComfyUI 通用)
› 社区话题 › Photoshop 平面设计社区 › 用 Pose ControlNet 精准控图:标准工作流(DrawThings / ComfyUI 通用)

- 作者帖子
- 2026-04-29 - 11:10 #131634

追光参与者很多人用 AI 画图,最大的痛点根本不是不会写提示词,而是“人物姿势总乱变”。同样输入“一个站立的人”,AI 可能随机生成几十种完全不同的姿态。做分镜、角色设计或视觉预演时,这种不确定性非常致命。
解决这个问题的核心工具就是 Pose ControlNet。它的作用很直接:把“人物怎么动”从 AI 的随机发挥中抽离出来,变成你可以完全掌控的固定框架。

Screenshot
下面以 DrawThings 为例,走一遍最清晰、最稳定的按照我们的预期动作生成图片的操作流程。文末附你提供的完整参数配置对照表,ComfyUI 用户可直接按相同数值平移。
核心逻辑: 先提取动作结构,再让 AI 按照我们预期的动作生成内容。把“随机抽卡”变成“可控生产”。
主模型: realistic_vision_v5.1
支持SD control net,能生成写实摄影照片,负责光影、材质与基础人体渲染。
LoRA:tcd_sd_v1.5
TCD蒸馏加速模块,重构收敛曲线,模拟出老照片效果,可通过调节权重控制画面风格。
ControlNet:controlnet_openpose_v1.1
姿态控制分支,全程(0~1)注入骨骼坐标,强制AI严格遵循参考动作,彻底杜绝肢体漂移,也可调节控制方式。
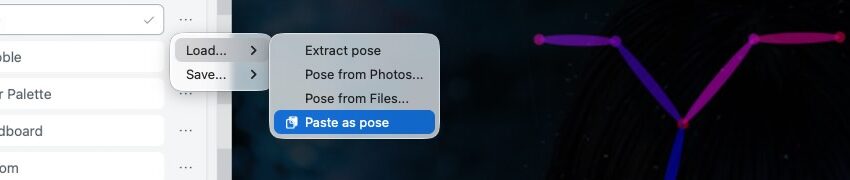
第一步:提取动作骨架
导入参考图(照片/截图/草图),在 ControlNet 中启用 OpenPose 预处理器。系统会自动识别人物关节,生成纯线条骨架图。此时 AI 读取的不再是画面像素,而是精确的肢体坐标与角度数据。
第二步:剥离并保存骨架
将生成的骨架图单独复制保存。原图完成使命,骨架成为独立可复用的“动作资产”。它不含光影、服饰或背景,只保留姿势结构,可随时跨项目调用。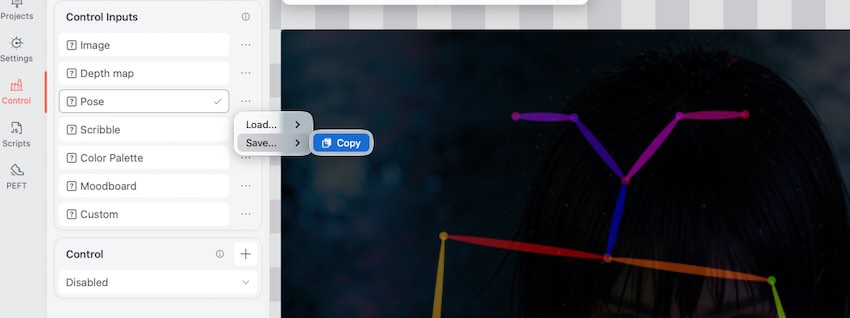
第三步:新建画布并载入控制
切换至文生图模式,新建 512×512 画布(SD1.5 原生安全尺寸)。将骨架图导入/粘贴到 ControlNet 的pose图层。 controlnetopenpose1.xv1.1f16.ckpt。
Screenshot
关键设置: 权重 1.0,介入区间 Start 0 / End 1(全程生效),控制模式选 balanced。这一步等于给 AI 套上动作外骨骼,生成全程不跑偏。
第四步:配置生成参数
底模选择 realisticvisionv5.1f16.ckpt。挂载 TCD LoRA(tcdsdv1.5loraf16.ckpt,权重 1.0)。
采样设置: 采样器选 DPM++ 2M Karras(DrawThings 编号 12),步数 16,CFG 5,种子固定以便复现。关闭高清修复(hiresFix: false),CLIP Skip 保持 1。
参数逻辑: TCD 蒸馏模型改变了收敛曲线,16 步+CFG 5 是官方黄金组合。低 CFG 避免提示词过度干预,把结构控制权完全让给 ControlNet;固定种子方便微调提示词,出满意结果后再切随机种子批量变体。{"batchSize":1,"refinerModel":"","seed":340867042,"batchCount":1,"tiledDiffusion":false,"upscaler":"","seedMode":2,"sharpness":0,"height":768,"strength":1,"clipSkip":1,"causalInferencePad":0,"sampler":12,"model":"realistic_vision_v5.1_f16.ckpt","guidanceScale":5,"maskBlur":2.5,"steps":16,"controls":[{"weight":1,"globalAveragePooling":false,"inputOverride":"","file":"controlnet_openpose_1.x_v1.1_f16.ckpt","guidanceStart":0,"noPrompt":false,"targetBlocks":[],"guidanceEnd":1,"controlImportance":"balanced","downSamplingRate":1}],"cfgZeroInitSteps":0,"maskBlurOutset":0,"cfgZeroStar":false,"loras":[{"mode":"all","file":"tcd_sd_v1.5_lora_f16.ckpt","weight":0.22}],"preserveOriginalAfterInpaint":true,"width":768,"faceRestoration":"","hiresFix":false,"tiledDecoding":false,"shift":1}小技巧:上方参数可以直接复制并粘贴到Draw things,即可实现全自动配置,可直接使用。
第五步:输入提示词并出图
姿势已被锁死,提示词只需专注三件事:角色身份、外观装备、场景氛围。无需再描述动作细节。点击生成,AI 会严格沿骨架“填色”,输出结构稳定、细节完整的画面。结构层(Pose 全程锁定) → 内容层(提示词定义角色与环境) → 渲染层(底模+TCD 低步数出图)
DrawThings 的面板设置与 ComfyUI 的节点连线逻辑完全一致:Load Checkpoint → LoRA Loader → ControlNet Apply (strength 1, 0~1) → KSampler (16步, cfg 5, dpmpp2m karras) → VAE Decode。参数平移即可 1:1 复现。
熟练此流程后,可叠加 Depth 控制景深、Lineart 固定服饰轮廓,或接入批量节点搭建分镜预演管线。
- 2026-04-29 - 11:41 #131644
追光参与者使用SD ControlNet pose精准控制AI表情、手指与姿势:进阶工作流
第一步:提取完整骨架(含脸/手)
访问「哩布哩布AI」网站,上传参考图。ControlNet 类型选 OpenPose,预处理器务必选择 OpenPose Full。系统将输出包含身体坐标、手指关键点与面部五官点位的完整骨架图。这是实现同步控制的数据基础。第二步:导入 DrawThings 图层
将生成的骨架图拖入 DT 的 Pose 图层,或放入draw things的控制当中的“自定义图层”(推荐,编辑权限更高)。此时画布已被全身坐标网格覆盖,AI 的生成范围被初步框定。第三步:手动精修(决胜关键)
AI 自动提取的骨架常有偏差,必须用 DT 内置工具修正:
画笔:补全缺失的指节与面部关键点
橡皮擦:删除错位节点、多余手指或干扰线
拖拽节点:微调手指弯曲角度、嘴角弧度与眼睛朝向
缩放工具:修正骨架与画布的比例关系
这一步直接决定最终同步精度,切勿跳过。
第四步:模型选择与生成设置
SD1.5 Pose对面部关键点与手指结构的权重敏感度极高,能稳定识别微表情与指节形态;而 SDXL/Kolors pose仅能识别动作,而不能处理手指和表情细节。
模型与控制网络的配置:
{"strength":1,"sharpness":0,"height":768,"seedMode":2,"shift":1,"faceRestoration":"","batchSize":1,"controls":[{"globalAveragePooling":false,"weight":1,"inputOverride":"","file":"controlnet_openpose_1.x_v1.1_f16.ckpt","guidanceStart":0,"noPrompt":false,"guidanceEnd":1,"targetBlocks":[],"controlImportance":"balanced","downSamplingRate":1}],"hiresFix":false,"causalInferencePad":0,"loras":[{"mode":"all","file":"tcd_sd_v1.5_lora_f16.ckpt","weight":0.01}],"seed":2234305494,"sampler":12,"preserveOriginalAfterInpaint":true,"steps":16,"maskBlur":2.5,"clipSkip":1,"cfgZeroStar":false,"tiledDecoding":false,"width":768,"batchCount":3,"tiledDiffusion":false,"upscaler":"","model":"realistic_vision_v5.1_f16.ckpt","refinerModel":"","guidanceScale":5,"cfgZeroInitSteps":0,"maskBlurOutset":0}控制逻辑拆解
姿势:由全身骨架坐标强约束
手指:依赖 SD1.5 的局部注意力机制+手动补点,可精准控制握拳/张开/手势
表情:靠面部关键点网格+低 CFG 配合,实现微笑/张嘴/视线同步
全骨架定框架,手动修细节,SD1.5 抓微结构。按此四步流程,即可彻底告别肢体漂移与表情随机,实现姿态、手势与五官的稳定同步。需 ComfyUI 节点对照或自动化批量管线可随时提供。
- 作者帖子


- 在下方一键注册,登录后就可以回复啦。