「AI图片处理」Qwen Image Edit 能做什么?六大核心能力与实际应用解析
› 社区话题 › Photoshop 平面设计社区 › 「AI图片处理」Qwen Image Edit 能做什么?六大核心能力与实际应用解析

- 作者帖子
- 2026-04-27 - 17:44 #131571

追光参与者随着生成式图像技术的发展,图像编辑正在从“工具操作”转向“语言驱动”,Qwen Image Edit、Fluxkelein2等模型正是这一趋势下的代表模型。它可以在本地(如 Draw Things)运行,通过简单的提示词完成复杂的图像生成与编辑任务。在许多场景中,它已经可以替代传统依赖 LoRA 或复杂流程的工作方式。
本文将系统梳理 Qwen Image Edit 的核心能力与实际应用场景。
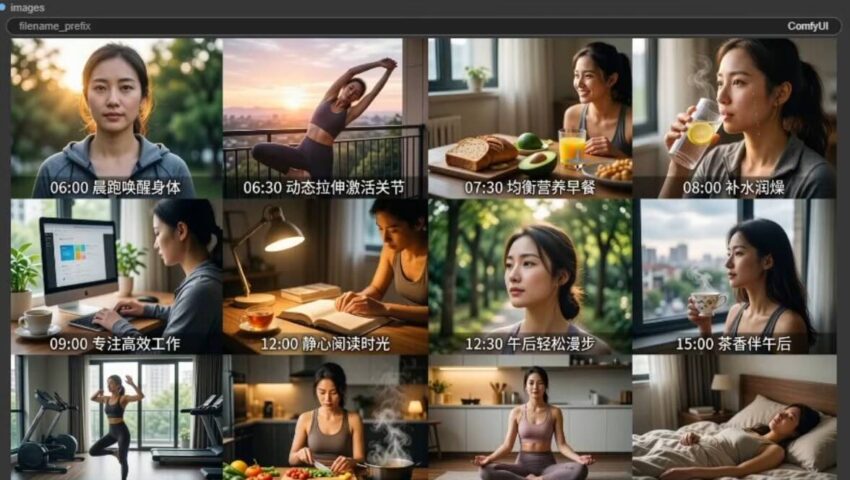
一、人物一致性与多场景生成
Screenshot
Qwen Image Edit 可以基于一张人物基础图,生成该角色在不同场景下的表现,同时保持人物外观的一致性。
例如,同一个人物可以被快速生成在工作、运动、旅行或日常生活等多种环境中,而无需重新建模或训练角色。
这一能力特别适用于连续内容创作,如剧情分镜、漫画制作或个人IP构建。
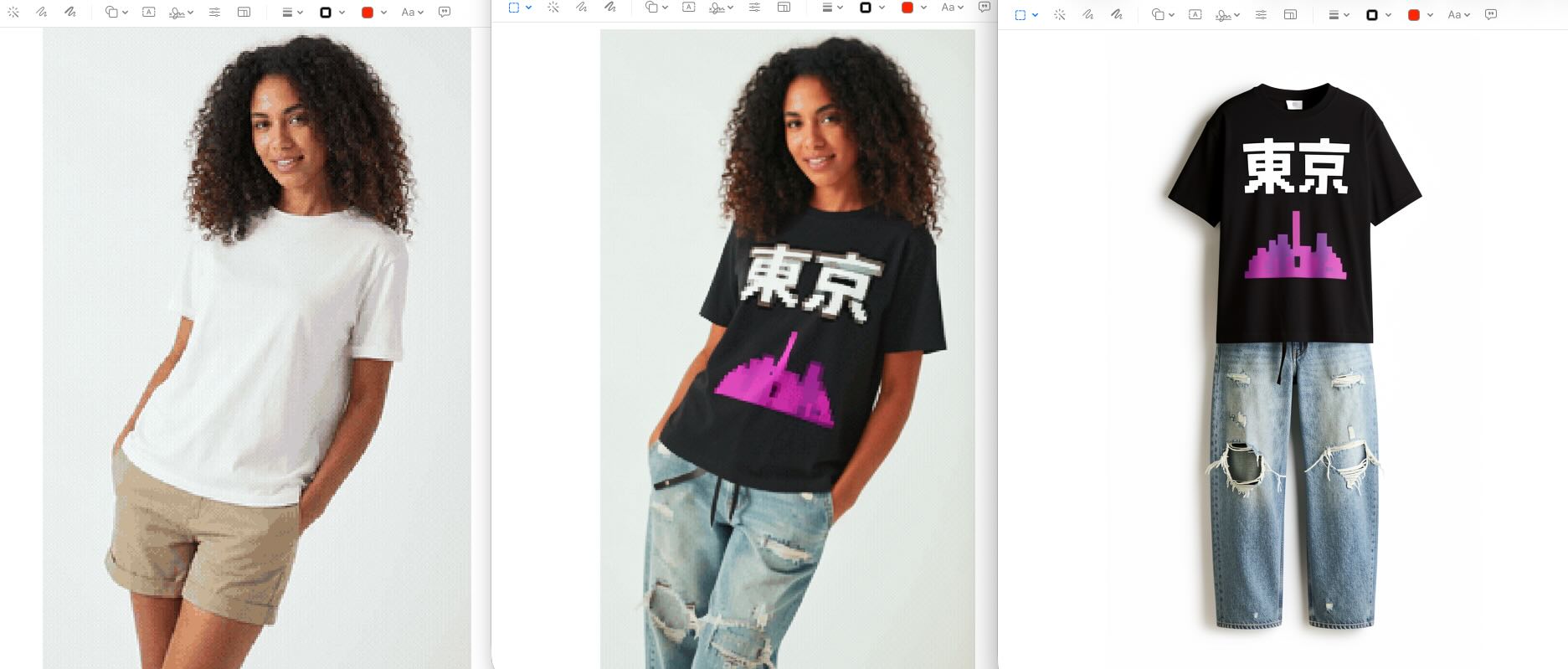
二、虚拟试穿能力
Screenshot
在没有模特或拍摄环境的情况下,Qwen Image Edit 依然可以完成高质量的服装展示。
只需提供服装图片,模型即可生成任意人物穿着该服装的效果,并保持服装细节与结构的一致性。同时,还支持多件服饰的组合。
此外,还可以将人物头部、服装与商品进行组合,用于生成广告或电商视觉内容。
三、图像融合
Qwen Image Edit 支持多图融合,并能够自动处理图像之间的过渡问题。即使输入图像存在拼接痕迹或边缘不自然,模型仍可以通过提示词实现:光影统一、色彩匹配、边缘平滑,这一能力显著降低了对传统 LoRA(如光影修复或融合模型)的依赖,使流程更加高效。

Screenshot
四、视角转换能力
模型具备一定的空间理解能力,可以对图像进行视角转换,例如:将人物从正面转换为侧面或背面;将室内场景转换为俯视视角;对画面进行局部放大或重构,在转换过程中,能够保持原有结构与元素的一致性,这在传统图像编辑流程中较难实现。
五、物体移除
Qwen Image Edit 可以通过简单的提示词移除图像中的指定元素,并自动补全背景内容。该功能具有以下特点:操作简单、生成速度快、补全效果自然,在实际应用中,这一能力已经可以替代部分传统修图工具的工作。
六、背景替换
在保持前景主体不变的情况下,模型可以对背景进行重建。例如,将人物置换到不同环境(如室内、商店或街景)中,同时自动调整光照与色彩,使整体画面保持一致。
这一能力在广告制作、视觉合成等场景中具有较高实用价值。
七、扩展功能
除了核心能力外,Qwen Image Edit 还支持多种基础与进阶操作,包括:风格转换(写实、插画等)、物体增加或删除、多元素创意组合、局部重绘(Inpainting)、图像扩展(Outpainting),其中,局部重绘可结合特定方法实现更精细的控制,例如通过指定区域进行定向生成。
八、当前限制
尽管功能强大,部分能力仍处于不稳定阶段,例如:精准文字修改(如海报改字)、基于创意板的复杂组合(Moodboard)、在实际使用中,这些功能仍有一定局限。
Qwen Image Edit 的核心价值在于,将复杂的图像编辑流程简化为基于提示词的操作方式。相比传统方法,其优势主要体现在:更低的使用门槛、更简洁的工作流程、更自然的生成效果
从长期来看,这类模型正在推动图像编辑从“工具驱动”走向“语言驱动”,并逐步改变内容创作的工作方式。
九、老旧破损照片修复

Screenshot
十、动作复刻
让人物A做出和人物B一样的动作。
- 2026-04-30 - 17:18 #131717
追光参与者今天测试了 Qwen Image Edit 2509/2511的换脸方法
新的流程是:首先将原图放在画布上,把需要替换的人脸作为第二张图放入创意板。直接用提示词替换通常会失败,因为模型会强行保持原图人脸一致性。因此关键步骤是“消除原脸干扰”。具体做法是在画布中使用画笔工具(不是橡皮),将原图人脸区域涂成实心颜色,例如绿色或棕色。

Screenshot
随后在提示词中明确指令,如“将图1绿色区域替换为图2的人脸”。这样模型会忽略原人脸特征,从创意板中提取目标人脸并完成融合。测试中英文提示词效果更稳定,推荐优先使用。
Draw Things替换人脸流程(Face Swap)使用flux2 和Qwen image edit换脸的俩种方法
分辨率方面建议使用768×768以提升生成速度。整体流程:导入原图 → 导入替换脸 → 涂抹人脸区域 → 输入提示词 → 生成。整个过程无需额外软件,操作连贯且效果自然,是目前较高效稳定的换脸方案之一。
- 作者帖子

- 在下方一键注册,登录后就可以回复啦。