【AI应用】Ultimate Vocal Remover(UVR)深度使用指南:原理、模型特点与实战用法
› 社区话题 › 📺 VFX Pipeline | 数字创意工作流 › 【AI应用】Ultimate Vocal Remover(UVR)深度使用指南:原理、模型特点与实战用法

- 作者帖子
- 2026-01-21 - 23:26 #131085

追光参与者Ultimate Vocal Remover(简称 UVR)是一款基于深度学习的音频源分离工具,专为高质量人声与伴奏拆分而设计。它集成了当前最先进的两类模型架构MDX-Net 与 Demucs(含 HDemucs/HTDemucs 系列),通过不同技术路径实现互补,既满足快速日常处理,也支持专业级音频工程需求。UVR 不仅适用于翻唱伴奏制作、Acapella 提取,还可用于影视后期、VFX 音频处理、Remix 创作等场景。

一、核心原理:两种技术路线,各有所长
UVR 的强大之处在于其融合了两种截然不同的 AI 分离范式:
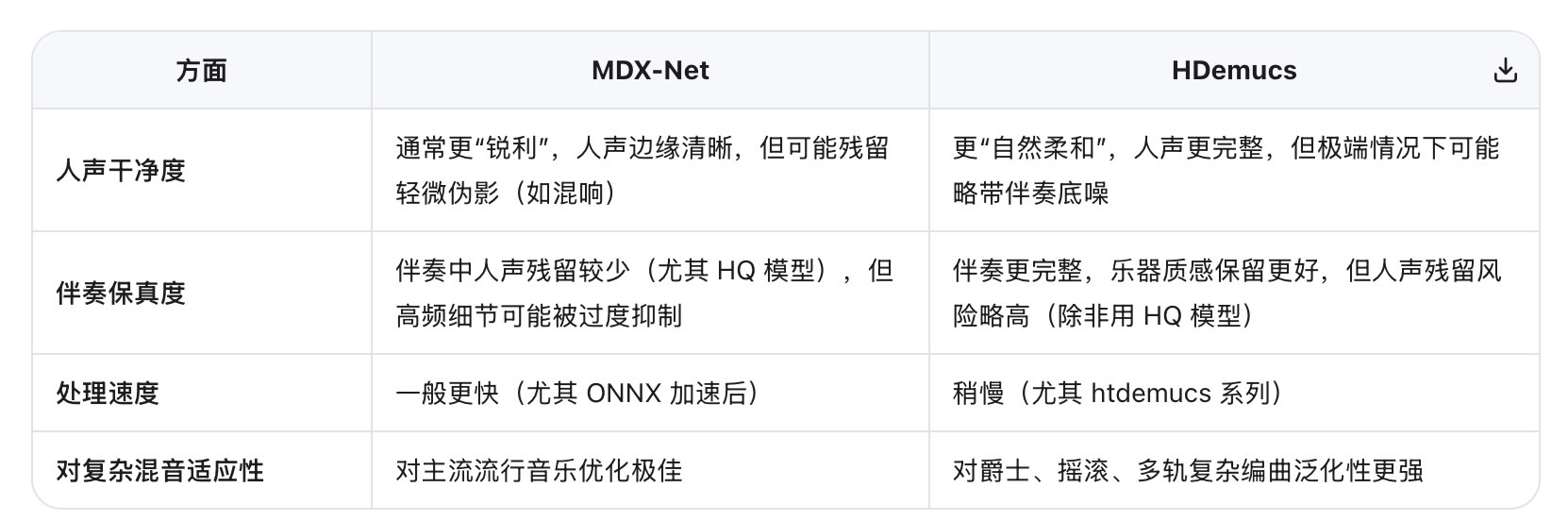
MDX-Net 基于频域掩码建模。它将音频转换为频谱图(如 STFT),通过训练神经网络识别并“擦除”人声或伴奏对应的频段,再逆变换回时域波形。这种方式对主流流行音乐高度优化,擅长实现“手术刀式”的干净分离,尤其在去除人声方面表现极致。

Screenshot
Demucs 系列(HDemucs / HTDemucs) 则采用端到端时域建模,直接在原始波形上进行分离。它结合时频信息,利用 RNN 或 Transformer 架构重建人声与各乐器轨道。这种方法更注重整体听感的自然性,保留混响、空间感和乐器质感,适合复杂编曲或对音乐性要求高的场景。
Screenshot
这两种方法并非竞争关系,而是互补工具:MDX-Net 追求“干净”,Demucs 追求“自然”。专业流程中,往往先用 Demucs 打底,再用 MDX-Net 修补残留,从而兼顾音乐性与工程精度。
二、模型详解:哪些值得用?怎么选?
(1)Demucs 系列 音乐感优先
Demucs 是 Meta 开发的开源分离架构,UVR 中集成的是其 v3/v4 版本。重点推荐以下三个:
htdemucsft(首选主力)
这是 Hybrid Transformer Demucs 的微调版(fine-tuned),在 MUSDB18-HQ 等高质量数据集上进一步优化。
特点:人声边缘清晰、低频分离干净、AI 痕迹最少,混响和尾音保留完整。
适用:90% 的流行歌曲人声提取、Acapella 制作、Remix 底层素材。
建议:作为所有分离任务的第一步。hdemucsmmi(备用王牌)
“mmi” 表示 multi-mono improved,是 HDemucs 的增强版,对立体声偏移、强混响等复杂情况鲁棒性更强。
特点:分离更稳,但人声略靠后,高频稍弱。
适用:EDM、电子音乐、人声被压得很深的密集编曲。htdemucs6s(多轨专用)
唯一支持六轨输出的公开模型:vocals、drums、bass、piano、guitar、other。
特点:可单独提取钢琴或吉他,但非相关歌曲中可能产生空轨或噪声。
适用:影视配乐剪辑、VFX 音频处理、需要分轨控制的创作场景。⚠️ 注意:Demucs v3(如 mdx、mdxextra)已过时,除非极端修补,否则无需使用。
(2)MDX-Net 系列 干净度优先
MDX-Net 是 UVR 团队基于改进 U-Net 架构开发的专用模型,强调“零人声残留”。
UVR-MDX-NET Main:人声修补主力,通用主模型,平衡人声与伴奏分离质量。
特点:泛化强、速度快,对居中人声效果优秀。
用法:不建议单独作为人声底,而是用于补充 htdemucsft 输出的高频细节。UVR-MDX-NET Inst HQ 1 / 2/3(伴奏专用)
“Inst HQ” 系列专为生成纯伴奏设计,训练目标就是“彻底去人声”。
HQ 1:激进抑制人声,适合 K-pop、华语流行等突出人声的歌曲,但可能轻微损伤高频。
HQ 2:更平衡,兼顾干净度与伴奏保真,推荐作为 HQ 1 的备选。适用:卡拉 OK、商用伴奏、翻唱工程宁可声音干一点,也不能有人声残留。HQ_3:更保守,保留更多伴奏细节,但可能留微量人声。复杂编曲、爵士、摇滚等。
❌ 其他如 Inst HQ 3、旧版 MDX 1/2/3 等,已被 HQ 系列覆盖,可安全删除。
三、实战用法:三套专业工作流
UVR 的真正价值不在“一键分离”,而在组合策略。以下是经过验证的三种高效流程:
🎤 场景一:人声最自然(专业 Remix / Acapella)
1. 用 htdemucsft 分离,获得自然、有空间感的人声。
2. 用 UVR-MDX-NET Main 再次分离人声。
3. 以 Demucs 人声为主干,在 DAW 中叠加 MDX 人声的高频部分(如 8kHz 以上)。
4. 结果:既有音乐性,又具备清晰度,AI 味极低。🎹 场景二:伴奏最干净(商用 / 卡拉 OK)
1. 直接使用 UVR-MDX-NET Inst HQ 1。
2. 若仍有微弱人声残留,换用 Inst HQ 2。
3. 原则:接受伴奏略“干”,但绝不容忍人声泄露。🎬 场景三:多轨分离(影视 / VFX / 二创)
1. 使用 htdemucs6s 一次性输出六轨。
2. 在后期软件中自由控制鼓、贝斯、钢琴等元素,适配画面节奏或特效需求。
3. 注意:非钢琴/吉他曲目中,对应轨道可能为空,需手动检查。四、参数与平台建议(Mac 用户)
Chunk Size:
Apple Silicon(M1/M2/M3):设为 352800
Intel Mac:设为 176400
(过大易爆内存,过小影响效率)
Overlap:建议 0.250.5,值越大结果越稳,但速度下降。
Ensemble 模式:新手勿用。先单模型试听,再决定是否混合。五、终极心法:专业分离 ≠ 一次完成
真正的高质量分离是一个分层流程:
1. Demucs 打底 → 决定音乐感与整体结构;
2. MDX-Net 修补 → 清除残留,提升工程精度;
3. 后期精修 → 用 EQ、iZotope RX 或 SpectraLayers 微调频段、去噪、修复瞬态。这也是为什么 Spleeter 等单模型工具常显得“半成品”它们只完成了第一步。而 UVR 提供的是一整套可组合、可迭代的音频分离工具箱。
UVR 的核心不是“哪个模型最强”,而是“如何根据素材选择工具,并通过组合逼近理想结果”。掌握 htdemucsft + MDX-Net Inst HQ + Main 这几个核心模型,配合上述工作流,你已具备接近专业音频工程师的分离能力。记住:好分离,是听出来的,不是算出来的多对比、多试听,才是提升的关键。
- 2026-01-21 - 23:27 #131086
追光参与者方法一|默认就好用(省心),大多数歌曲
步骤:
htdemucs_ft → 完成
判断: 听起来自然 = 停手
原则: 不追求一次就“最干净”方法二|人声更清晰(专业)
人声重要 / remix
步骤:
htdemucs_ft → UVR-MDX-NET Main
用法:
• 以 Demucs 人声为主
• MDX 只补高频方法三|伴奏最干净(工程)
卡拉 OK / 商用
步骤:
UVR-MDX-NET Inst HQ 1
不够干净 → Inst HQ 2
原则: 宁可干,不要人声残留 - 2026-01-23 - 09:30 #131108
追光参与者UVR支持的完整模型分类清单以及uvr下载中心可下载的模型:
1. Demucs 系列(Meta 官方及衍生)
Demucs v4
htdemucsft
hdemucsmmi
htdemucs6s
Demucs v3
mdx
mdxq
mdxextra
mdxextraq
repromdxa
repromdxatimeonly
UVR Model(UVR 对 Demucs v3 的封装)2. MDX-Net 系列(UVR 基于 Demucs v3 改进)
HQ(High Quality)系列
UVR-MDX-NET Inst HQ 1
UVR-MDX-NET Inst HQ 2
UVR-MDX-NET Inst HQ 4
UVR-MDX-NET Inst HQ 5
Main / Standard 系列
UVR-MDX-NET Main
UVR-MDX-NET Inst Main
基础系列
UVR-MDX-NET 1
UVR-MDX-NET 2
UVR-MDX-NET 3
UVR-MDX-NET Inst 13. VR Arch Single Model 系列(UVR 原生频域模型,非 Demucs 架构)
注:此系列基于频谱掩码(Spectral Subtraction / UNet-like)设计,常用于人声/伴奏分离、去噪、去混响等。
3.1 通用分离模型(HP / SP 命名)
HP 系列(High Precision)
2HP-UVR
3HP-Vocal-UVR
4HP-Vocal-UVR
5HP-Karaoke-UVR
6HP-Karaoke-UVR
7HP2-UVR
8HP2-UVR
9HP2-UVR
17HP-WindInst-UVR(专为风噪/乐器优化)
SP 系列(Standard Precision,多频段)
10SP-UVR-2B-32000-1
11SP-UVR-2B-32000-2
12SP-UVR-3B-44100
13SP-UVR-4B-44100-1
14SP-UVR-4B-44100-2
15SP-UVR-MID-44100-1
16SP-UVR-MID-44100-23.2 专用处理模型(由 FoxJoy 等开发者贡献)
去回声 / 去混响
UVR-De-Echo-Aggressive by FoxJoy
UVR-De-Echo-Normal by FoxJoy
UVR-DeEcho-DeReverb by FoxJoy(注:原文有拼写变体,统一为标准名)
降噪
UVR-DeNoise by FoxJoy
多轨影视音效分离(BVE = Background/Vocal/Effects)
UVR-BVE-4BSN-44100-13.3 MGM 系列(Multi-Genre Mastering,v4 版本)
MGMHIGHENDv4
MGMLOWENDAv4
MGMLOWENDBv4
MGMMAINv4MGM 系列针对不同频段(低频/高频)和音乐风格优化,适用于高质量母带级分离。
4. Roformer 系列(基于 Transformer 的先进分离器)
BS-Roformer(Band-Split)
BS-Roformer-Viperx-1297
BS-Roformer-Viperx-1296
BS-Roformer-Viperx-1053
BS-Roformer-Inst-EXP-Value-Residual (by Unwa)
MelBand Roformer(Mel 频带建模)
Mel-Roformer-Viperx-1143
MelBand Roformer Kim | Inst V1 by Unwa
MelBand Roformer Kim | Inst V2 by Unwa
MelBand Roformer Kim | InstVoc Duality V1 by Unwa
MelBand Roformer Kim | InstVoc Duality V2 by Unwa
MelBand Roformer Kim | Inst V1 (E) by Unwa
MelBand Roformer Kim(基础版)
特殊用途
Karaoke MelBand Roformer (by aufr33 & viperx)
BS Roformer Dereverb (anvuew edition)5. SCNet 系列(Conv-TasNet 衍生)
4-stems SCNetMUSDB18 (by starrytong)
4-stems SCNet Large (by starrytong)
4-stems SCNet-XL6. 其他专用模型
Phantom Centre extraction (by wesleyr36) 中置声道提取
Cinematic Bandit Plus (by kwatcharasupat)
Cinematic Bandit v2 Multilang I (by kwatcharasupat) - 2026-01-23 - 09:47 #131112
追光参与者在 UVR(Ultimate Vocal Remover)测试版中的Roformer、SCNet 和 Bandit 模型
Roformer:基于旋转位置编码的Transformer,能精准捕捉人声与伴奏在频谱中的长程依赖关系和相位结构。对混响强、人声偏移、多和声的复杂歌曲表现显著优于旧模型。
SCNet(Spectral Complex Network):同时建模频谱的幅度 + 相位(传统模型只处理幅度),输出波形更自然,几乎无“金属感”伪影,人声边缘极其干净。
Bandit:轻量级但高效,采用频带自适应分离策略,在低资源下仍能保持高精度,特别适合高频细节(如齿音、气声)保留。一、Roformer 系列 当前分离质量天花板
基于频带拆分 + Transformer,细节保留极佳,适合高保真需求。最佳通用人声/伴奏分离
BS-Roformer-Viperx-1297
→ 分离干净、人声残留少、伴奏完整性高,综合最强,适合流行、电子、摇滚等多数风格。
MelBand Roformer Kim | Inst V2 by Unwa
→ 对复杂编曲(如交响、爵士)表现优异,乐器分离更自然,适合专业制作。特殊用途推荐
Karaoke MelBand Roformer (by aufr33 & viperx)
→ 专为人声+伴奏二分优化,适合 K 歌、翻唱。
BS Roformer Dereverb (anvuew edition)
→ 去混响效果目前最佳,适合修复现场录音或会议音频。提示:Roformer 模型对 GPU 显存要求较高(建议 ≥6GB),但质量远超传统模型。
二、SCNet 系列 轻量高效,适合快速处理
基于 Conv-TasNet 改进,速度快,资源占用低。最佳平衡选择
4-stems SCNet Large (by starrytong)
→ 在速度与质量间取得良好平衡,支持四轨分离(人声、鼓、贝斯、其他),适合批量处理或中低配设备。注意:SCNet-XL 虽参数更大,但提升有限,且易过拟合;Large 版本更实用。
三、Bandit 系列 影视/多语言音轨分离首选
专为电影、剧集、多语言内容设计,能分离对白、背景音乐、音效。最佳影视处理
Cinematic Bandit Plus (by kwatcharasupat)
→ 支持多语言对白提取,背景音乐/音效抑制强,影视工作者首选。
Cinematic Bandit v2 Multilang I
→ 多语言兼容性更好,适合非英语内容(如中文、日语剧集)。四、其他专用模型
Phantom Centre extraction (by wesleyr36)→ 从中置声道精准提取人声(适合立体声混音),常用于修复老歌。总结推荐表(按用途)
用途———————推荐模型
最高质量人声/伴奏分离——–BS-Roformer-Viperx-1297 |
复杂编曲分离—————MelBand Roformer Kim \\| Inst V2 |
去混响 / 去回声————-BS Roformer Dereverb 或 UVR-DeEcho-DeReverb |
影视对白提取—————Cinematic Bandit Plus |
快速批量处理—————4-stems SCNet Large |
日常通用分离—————UVR-MDX-NET Main |
中置人声提取—————Phantom Centre extraction |使用建议:
追求极致音质 → 选 Roformer(尤其 1297)。
处理影视/多语言 → 选 Bandit Plus。
设备性能有限 → 选 SCNet Large 或 MDX-NET Main。
需要音频修复(去混响/降噪)→ 优先用 FoxJoy 的 VR Arch 专用模型。当然我个人更推荐使用waves中的dereverb处理,具有百分百的手动控制能力。
- 作者帖子

- 在下方一键注册,登录后就可以回复啦。