Ai应用RAG知识库构建与部署资源使用方法汇总
› 社区话题 › 📺 VFX Pipeline | 数字创意工作流 › Ai应用RAG知识库构建与部署资源使用方法汇总

- 作者帖子
- 2025-03-22 - 10:52 #128211

追光参与者Ai的发展给更多行业带来了便利,但如何应用到实际工作中成为生产力的一部分也是我一直在思考的问题。通过在api以及本地部署模型,进行前端调用,以及RAG知识库构建、通过大模型训练精微模型,每一种方式我都尝试过。在这个过程中也搜集了一些有用的站点。将这些记录在这里,以后还会继续更新。
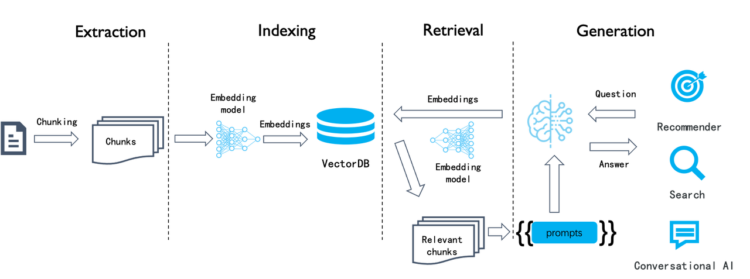
1. 本地部署大模型(LLM)
选择合适的模型:选择适合需求的 LLM
使用Ollama和LM Studio部署各大产商开源模型的流程2、嵌入模型(Embeddings):
生成嵌入向量:使用合适的嵌入模型(如 BERT、Sentence-BERT)将文本内容转化为固定维度的嵌入向量。调整嵌入模型的参数,确保生成的嵌入能有效表示文本内容,提升搜索的准确性和相关性。bge-m3(1024维度);bge-large-zh(1024维度);text-embedding-nomic(768维度)
Embedding 3-Large (3572维度);Embedding Ada-002(1536维度)
这些是你当前使用或测试的嵌入模型,每个模型的维度不同,适用于不同的向量数据库存储和检索需求。你的 Qdrant 部署 是可以支持不同维度的嵌入向量的,所以你可以在同一个数据库中存储 1024维、768维、1536维、3572维 的数据,而不需要重新设定固定维度。
各嵌入模型的特点与适用场景
1.bge-m3(1024维)
适用于多任务嵌入(MTEB),擅长多模态任务。
适用场景:检索增强生成(RAG)、文本匹配、推荐系统。2.bge-large-zh(1024维)
专为中文优化的 BGE 系列模型,擅长中文向量检索任务。
适用场景:中文搜索、问答系统、信息检索。3.text-embedding-nomic(768维)
轻量级嵌入模型,适合存储与检索效率要求高的应用。
适用场景:快速查询、小型嵌入数据库、资源受限的环境。4.Embedding 3-Large(3572维)
OpenAI 最新的大规模嵌入模型,维度极高,适用于精细化检索。
适用场景:高精度向量匹配、大规模知识库。5.Embedding Ada-002(1536维)
OpenAI 提供的主流嵌入模型,均衡了性能和成本,广泛用于 RAG 系统。
适用场景:大规模知识库检索、问答系统、语义搜索。
- 2025-04-01 - 12:03 #128244
追光参与者3. 向量数据库
向量数据库(Vector Database)用于存储、索引和高效检索 高维向量,常用于 语义搜索、推荐系统、异常检测 等场景。例如,文本、图像、音频都可以转换为向量,以便进行相似性搜索。将数据转换为 嵌入向量,嵌入向量存储与检索。Pinecone 和 Qdrant 进行对比,选择更适合你的 向量数据库需求?
两者都是 高效的向量数据库,但它们有一些关键区别:
Pinecone vs. Qdrant 对比
特性
Pinecone
Qdrant
部署方式
云端 SaaS(Pinecone 提供托管)
本地部署 / 自托管(Docker, Bare Metal)
存储格式
向量存储(索引自动管理)
向量 + 元数据(可定制索引)
索引技术
HNSW(自动管理)
HNSW(可自定义参数)
查询方式
仅向量搜索
向量 + BM25 关键词搜索
多维度支持
需要单独索引不同维度的向量
可以存储不同维度的向量(如 768、1024、1536、3572)
可扩展性
自动扩展,适用于大规模应用
需要手动扩展,但控制权更强
访问控制
API Key 认证
API Key 或 自定义身份验证
适合场景
商业 SaaS,简单集成
需要自定义,部署灵活
向量数据库在进行 近似最近邻搜索(ANN) 时,通常需要计算向量间的相似度。以下是几种常见的相似度度量方式:
1. 余弦相似度(Cosine Similarity)
特点:衡量两个向量的方向是否相似(角度越小,相似度越高),适用于文本搜索、推荐系统(例如嵌入模型生成的文本向量).2. 欧几里得距离(Euclidean Distance)
特点:衡量两点间的直线距离;适用于 像检索、空间数据分析
3. 曼哈顿距离(Manhattan Distance / L1 距离)
特点:适用于高维稀疏数据(如推荐系统中的用户行为数据) - 2025-04-14 - 10:14 #128251
追光参与者Qdrant向量数据库部署方法以及使用方法
Qdrant 是一个高性能的向量搜索引擎,专为存储和检索高维向量数据而设计。它支持语义搜索、推荐系统、图像检索等应用场景。Qdrant 提供了开源版本以及在线托管服务(Qdrant Cloud),开发者可以轻松部署和使用。以下是 Qdrant 的基本使用流程:
一、安装Qdrant(使用docker安装)
1、拉取静像docker pull docker.m.daocloud.io/qdrant/qdrant2、运行镜像(在运行前必须要设置api密钥)
docker run -d -p 6333:6333 -p 6334:6334 -e QDRANT__SERVICE__API_KEY=密钥 -v /挂载的磁盘路径/:/qdrant/storage --name NewVFX_Vector docker.m.daocloud.io/qdrant/qdrant:latest3、默认在 localhost:6333 运行
打开浏览器输入地址后即可打开管理界面,这里会弹出密钥验证,输入运行时候设置的密钥即可。4、创建数据库
PUT collections/star_charts { "vectors": { "size": 1024, "distance": "Dot" } }//star_charts 是数据库名(随意更改),size是数据库维度,不同的Emb模型有不同的数据维度;distance是计算方式。
5、创建好数据库后,在应用内连接
服务器:localhost:6333 ;数据库名:star_charts;apikey:密钥6、数据库的备份和还原
Qdrant支持数据库快照,可以将数据库打快照并下载备份,也可以上传快照进行还原。点击进入数据库后,点击Snapshot,即可创建快照并下载。也可以在collection界面上传快照对数据进行还原。
二、 Qdrant 在线托管数据库的使用方法
Qdrant Cloud 提供完全托管的在线数据库服务,无需管理底层基础设施。自动扩展功能,适应不同规模的工作负载。
以下是使用 Qdrant 托管数据库 的详细步骤:
1. 访问 Qdrant Cloud,并注册一个新账户。
2. 创建集群
登录后进入控制台 ,将看到 Qdrant Cloud 的管理界面。创建新集群
– 点击“Create Cluster”按钮。
– 选择适合需求的配置(如性能模式、区域位置等)。
– 输入集群名称,并确认创建。等待集群启动
创建完成后,Qdrant 将分配一个托管的集群实例。可以在控制台中查看集群的状态和详细信息。3. 获取 API 密钥和连接信息
API 密钥
在 Qdrant Cloud 控制台中,找到集群详情页面,复制生成的 API 密钥。这个密钥用于身份验证。主机地址
同样在集群详情页面中,您可以找到分配给您的 主机地址(例如:`https://your-cluster-id.aws.qdrant.cloud`)。这是与 Qdrant 集群交互的入口。 - 2025-04-16 - 10:31 #128259
追光参与者Pinecone向量数据库的在线使用方法
Pinecone 是一个专为机器学习和人工智能应用设计的托管向量数据库服务。它主要用于存储、检索和管理高维向量数据(如嵌入向量),并支持高效的相似性搜索(Similarity Search)。Pinecone 的核心目标是帮助开发者轻松构建和部署基于向量的应用程序,例如推荐系统、语义搜索、异常检测等。
1. 登录并创建项目
访问 Pinecone 网站:打开 [Pinecone 官网]并登录账户。
进入仪表板:成功登录后,将看到一个仪表板界面。
创建新项目:在免费层级(Free Tier)下启动一个新项目。点击“创建项目”按钮,并为项目命名。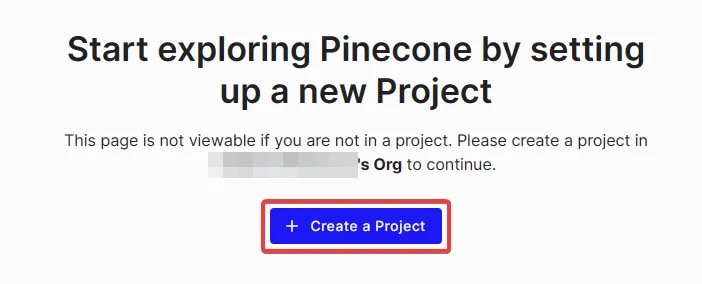
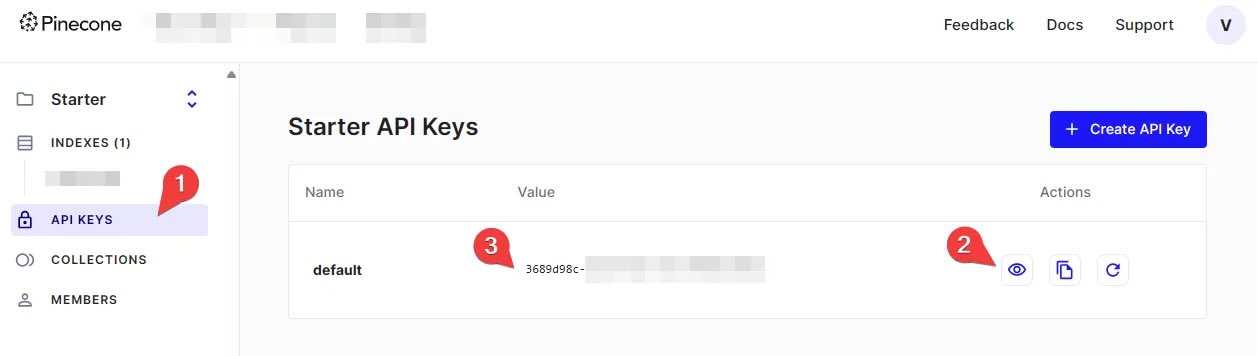
2. 获取 API 密钥
导航到 API 密钥选项卡:在仪表板中找到并点击“API 密钥”选项卡。
检查默认密钥:如果已经有一个名为“默认”的 API 密钥,则可以直接使用它。如果没有,点击“创建 API 密钥”按钮生成一个新的密钥。
显示并复制密钥:点击眼睛图标(👁️)以显示密钥的值,然后将其复制并妥善保存。这个密钥将在后续步骤中用于身份验证。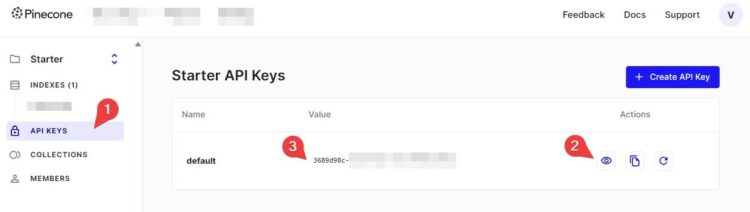
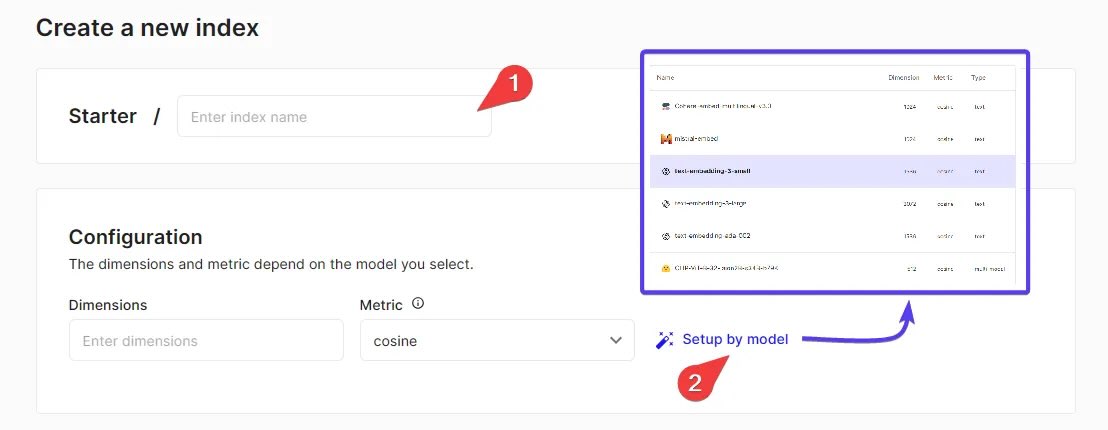
3. 创建索引
选择索引名称和维度:在仪表板中,点击“创建索引”按钮。为索引指定一个名称,并设置其维度(Dimension)。
注意:索引的维度应与您在 AI 引擎设置中的嵌入向量维度相匹配。例如,在“AI 默认环境 > 嵌入”中找到嵌入模型的维度,并确保它们一致。
选择配置选项:使用“按型号设置”选项,根据需求选择合适的配置(如性能模式、Pod 类型等)。
完成创建:确认设置后,点击“创建”按钮以生成索引。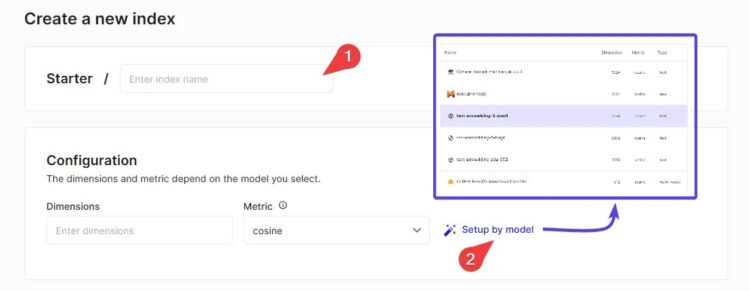
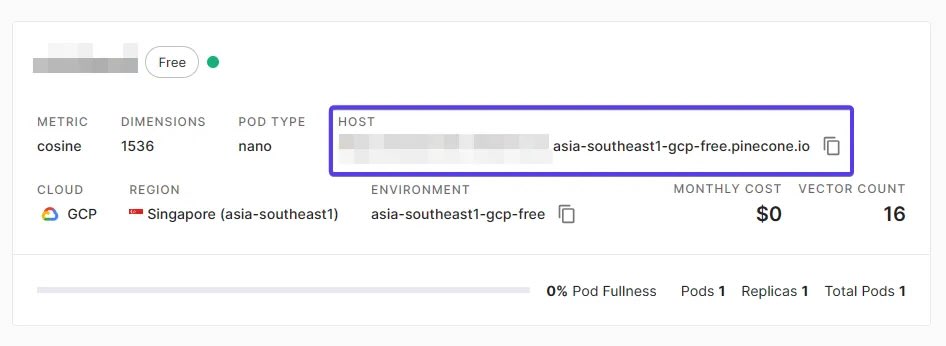
4. 获取主机值
查找主机地址:在索引创建完成后,可以从仪表板中找到该索引的“主机”(Host)值。
记录主机值:将主机值复制下来,因为需要在 AI 引擎中使用它来连接到 Pinecone 服务。
- 作者帖子

- 在下方一键注册,登录后就可以回复啦。