Draw Things for Mac 深度设置指南:榨干 Apple Silicon 的 AI 绘图潜力
› 社区话题 › 📺 VFX Pipeline | 数字创意工作流 › Draw Things 快速上手指南:从零到一的 AI 绘画之旅 › Draw Things for Mac 深度设置指南:榨干 Apple Silicon 的 AI 绘图潜力
追光
Draw Things for Mac 深度设置指南:榨干 Apple Silicon 的 AI 绘图潜力
Draw Things 是目前 macOS 平台上最强大的本地 Stable Diffusion 客户端之一。它充分利用了 Apple Silicon (M1/M2/M3 系列) 的 Metal 图形架构、统一内存架构 (Unified Memory) 以及神经网络引擎 (Neural Engine)。
设置选项,结合软件机制与硬件特性,以下是对关键参数的深度解析与优化建议。
一、 计算资源分配 (Server Offload) 本地/云端进行计算
核心逻辑: 决定“谁来干活”。
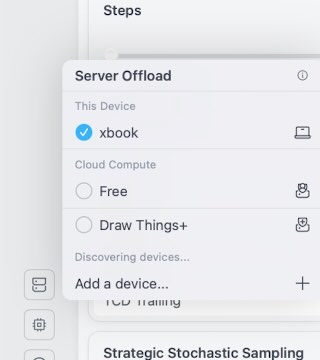
This Device (xbook): 勾选本地设备/ Free(免费版) /Drathings订阅版。
本地设备名: 这意味着所有的 AI 计算(生成图像)都在你的 Mac 本地进行。
硬件建议: 对于 M1/M2/M3 芯片,本地运行通常比免费的云端服务更快且隐私性更好。只要你的内存(RAM)足够(推荐 16GB 及以上跑 SDXL,8GB 跑 SD 1.5),本地运行是最佳选择。
Cloud Compute (Free / Draw Things+):
这是云端算力。如果你的 Mac 配置较低(如 8GB 内存跑 SDXL 爆显存),或者你需要极高速度的生成,可以考虑开启。但在本地硬件足够的情况下,关闭它可以节省订阅费用并保护隐私。
二、 核心性能与加速 (Performance & Acceleration)
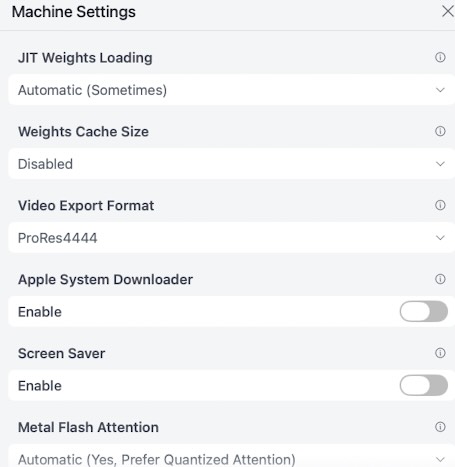
Screenshot
这是 Draw Things 的精髓所在,直接决定了出图速度和显存占用。
1. Metal Flash Attention
当前设置: Automatic (Yes, Prefer Quantized Attention)
深度解析: 这是最重要的设置之一。 Flash Attention 是一种优化的注意力机制算法,能显著降低显存(VRAM)占用并提高计算速度。
Prefer Quantized Attention: 对于量化模型(如 4-bit, 8-bit 模型),使用量化的 Flash Attention 效率极高。
建议: 保持默认。这能帮你在使用 SDXL 等大图模型时,避免 \”Out of Memory\” 错误。
2. Use Apple Neural Engine (ANE) for 8-bit S Models
当前设置: Yes
深度解析: Apple Silicon 芯片除了 CPU 和 GPU,还有一个专门跑 AI 的 NPU (Neural Engine)。
原理: 对于 8-bit 量化的 Stable Diffusion 模型,ANE 的处理效率极高,且几乎不占用 GPU 资源,甚至可以在后台运行而不影响你打游戏或看视频。
建议: 强烈推荐开启。 这是 Mac 端跑图的“物理外挂”。
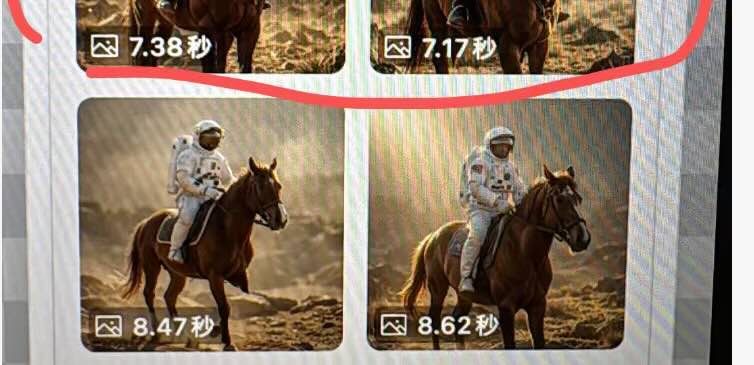
实测结果,上方为没有开启加速的,下方为开启加速后的结果。
特别提示:在M5芯片的设备上,开启后会降低10-15%的处理速度,但会更加节能。
3. CoreML 设置 (SD 1.5)
当前设置:
Use CoreML for SD 1.5 If Possible: Automatic (No)
Use CoreML w/ LoRA for SD 1.5: Automatic (No)
深度解析: CoreML 是苹果原生的机器学习框架。
优势: 速度极快(通常比 Metal 快 2-3 倍),功耗极低。
劣势: 模型需要专门转换(.mlmodel 格式),且对新出的社区模型(尤其是带复杂 LoRA 的)支持不如 Metal 原生好,兼容性有时会有问题。
设置分析: 你选择了 No,说明你更倾向于使用通用的 Metal 后端。这通常是为了兼容性。如果你发现出图报错,或者想用最新的 Civitai 模型,选 No 是稳妥的。如果你追求极致速度且只用基础 SD 1.5 模型,可以尝试改为 Yes。
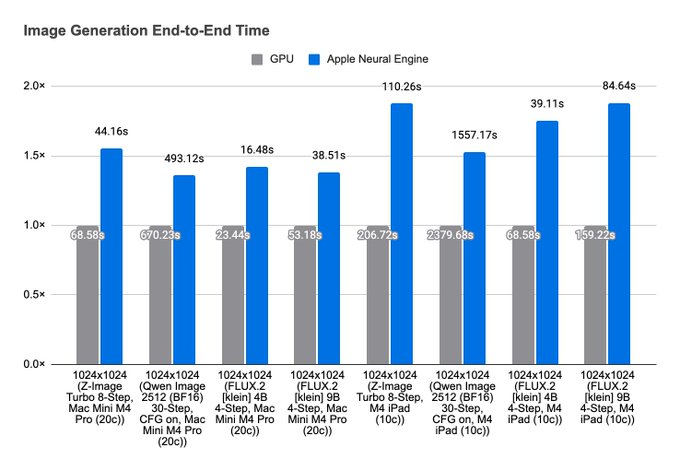
Apple Neural Engine (ANE) 一直是 Apple 设备上用于本地推理的有趣硬件,在 Draw Things 1.20260410.1 版本中,为 M3 和 M4 设备上的 8 位 S 模型添加了 Apple 神经网络引擎支持。在 M4 上,速度提升最高可达 1.8 倍。在 M3、M4 和 M5 上,还能降低能耗并降低运行温度。关键变化在于 CoreML 不再负责端到端推理。相反,其用作运行时内部特定操作的加速器。
数据来源:作者liuliu的X页面
8 bit S模型 是用于 int8 权重的格式,其中包含按行缩放的因子。在 ANE 架构中,int8 矩阵乘法也是唯一能够接近所宣称的 38 TFLOPs 吞吐量的途径,从而使该架构具有价值。换句话说,macOS 26 / iOS 26 中对直接 int8 交接的支持使得调用模型切实可行,而 int8 矩阵乘法的性能则使其值得采用。
三、 模型管理与内存优化 (Model Management)
1. Keep Model in Memory for SD 1.5 & SDXL
当前设置: Automatic (Preload)
深度解析: 决定是否将模型权重一直留在内存中。
Preload (预加载): 模型启动时加载,生成完不卸载。
优点: 连续出图速度极快,不需要反复读取硬盘。
缺点: 极度吃内存。
硬件建议:
16GB/24GB/32GB+ 内存: 保持 Preload,体验丝滑。
8GB 内存: 建议改为 Automatic (Unload) 或手动卸载,否则开一个 SDXL 模型,系统就会开始使用 Swap (虚拟内存),导致电脑卡顿甚至彩虹球。
2. Merge LoRA
当前设置: Not for Quantized Models
深度解析: LoRA 是微调模型。通常 LoRA 是动态加载的。
原理: 这个选项决定是否在生成前把 LoRA 合并进主模型权重里。
为什么选 Not for Quantized: 量化模型(4-bit/8-bit)精度较低,直接合并 LoRA 可能会导致精度进一步丢失或计算错误。保持分离加载(On-the-fly)是更安全、兼容性更好的做法。
3. Weights Cache Size
当前设置: Disabled
深度解析: 缓存权重文件以加快下次加载。
建议: 如果你的硬盘空间紧张(SD 模型很大),可以 Disabled。如果硬盘充裕,开启它可以减少模型切换时的等待时间。
四、 界面与体验 (UI & UX)
1. Show Generation Time
当前设置: Enable (开)
解析: 显示每张图花了多少秒。这是衡量硬件性能和调试参数(如 Steps, CFG)的重要指标,建议开启。
2. Use High Resolution Preview When Possible
当前设置: Enable (开)
解析: 在生成过程中提供高质量的预览图,而不是模糊的缩略图。
代价: 会轻微增加计算负担,但在现代 Mac 上几乎可以忽略不计。开启后体验更好。
3. Lightning Draft
当前设置: Automatic (No)
解析: 这是一个类似 SDXL Lightning 的快速生成模式。
原理: 用极少的步数(如 1-4 步)生成图像。
建议: 目前 SDXL Lightning 技术还在演进,设为 Automatic (No) 意味着默认不强制使用,保持标准生成的稳定性。如果你需要快速出草图,可以手动开启。
五、 其他高级设置
截图对应: 第二张图 (Video), 第四张图 (Privacy, Temporary)
1. Video Export Format: ProRes4444
解析: 你选择了苹果专业的高画质视频格式。
场景: 这说明你可能在使用 Draw Things 生成 AI 视频 (Deforum/AnimateDiff)。ProRes 4444 支持 Alpha 通道(透明背景)且画质无损,非常适合后期剪辑,但文件体积巨大。确保你的硬盘空间充足。
2. Temporary Directory: Cleanup
解析: 自动清理临时文件。AI 绘图会产生大量缓存(Latents, 中间步骤图),开启自动清理可以防止硬盘被瞬间塞满。
3. Privacy Pass: Enable (关)
解析: 这是一个匿名访问网络的凭证(类似于 Cloudflare 的隐私通行)。如果你不需要访问某些受保护的外部资源,关闭即可,能减少网络验证的延迟。
总结:针对你的配置 (xbook) 的优化建议
从截图来看,你的设置偏向于稳定、兼容和高质量,而不是极致的速度(因为你关掉了 CoreML 和预加载的强制项,虽然 Preload 是开的)。
建议:
1. 内存监控: 如开了 Keep Model in Memory (Preload),请密切观察 Mac 的“活动监视器”。如果是 8GB 内存机器,跑 SDXL 时请务必把这个改成 Unload。
2. CoreML 尝试: 如果主要玩 SD 1.5 且觉得速度慢,试着把 Use CoreML for SD 1.5 改为 Yes。速度会有质的飞跃。
3. Flash Attention 保持开启: 你的 Prefer Quantized Attention 设置非常棒,这是利用 Apple Silicon 算力的关键。
4. LoRA 策略: Not for Quantized Models 的设置很理智,避免了很多玄学报错。